STOC 2016 just ended and it included many great results with one highlight of course being Laci Babai’s quasipolynomial time algorithm for graph isomorphism. But today I wanted to mention another paper that I found quite interesting and reminded me of the famous Tolstoy quote that
Happy families are all alike; every unhappy family is unhappy in its own way.
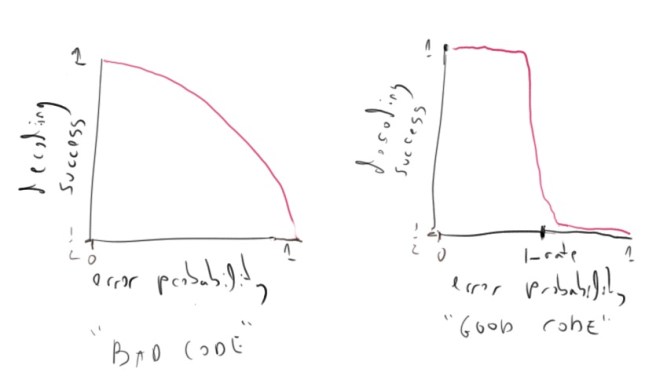
I am talking about the work Reed-Muller Codes Achieve Capacity on Erasure Channels by Shrinivas Kudekar, Santhosh Kumar, Marco Mondelli, Henry D. Pfister, Eren Sasoglu and Rudiger Urbanke. We are used to thinking of some error correcting codes as being “better” than others in the sense that they have fewer decoding errors. But it turns out that in some sense all codes of a given rate have the same average number of errors. The only difference is that “bad” codes (such as the repetition code), have a fairly “smooth” error profile in the sense that the probability of decoding success decays essentially like a low degree polynomial with the fraction of errors, while for “good” codes the decay is like a step function, where one can succeed with probability  when the error is smaller than some
when the error is smaller than some  but this probability quickly decays to half when the error passes .
but this probability quickly decays to half when the error passes .
Specifically, if  is a linear code of dimension
is a linear code of dimension  and
and ![p \in [0,1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , we let
, we let  be the random variable over
be the random variable over 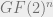 that is obtained by sampling a random codeword
that is obtained by sampling a random codeword  in
in 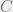 and erasing (i.e., replacing it with
and erasing (i.e., replacing it with  ) every coordinate
) every coordinate  independently with probability
independently with probability  . Then we define
. Then we define  to be the average over all of the conditional entropy of
to be the average over all of the conditional entropy of  given
given  . Note that for linear codes, the coordinate is either completely fixed by
. Note that for linear codes, the coordinate is either completely fixed by  or it is a completely uniform bit, and hence can be thought of as the expected number of the coordinates that we won’t be able to decode with probability better than half from a
or it is a completely uniform bit, and hence can be thought of as the expected number of the coordinates that we won’t be able to decode with probability better than half from a  -sized random subset of the remaining coordinates.
-sized random subset of the remaining coordinates.
One formalization of this notion that all codes have the same average number of errors is known as the Area Law for EXIT functions which states that for every code of dimension , the integral  is a fixed constant independent of . In particular note that if is the simple “repetition code” where we simply repeat every symbol
is a fixed constant independent of . In particular note that if is the simple “repetition code” where we simply repeat every symbol  times, then the probability we can’t decode some coordinate from the remaining ones (in which case the entropy is one) is exactly
times, then the probability we can’t decode some coordinate from the remaining ones (in which case the entropy is one) is exactly  where is the erasure probability. Hence in this case we can easily compute the integral
where is the erasure probability. Hence in this case we can easily compute the integral  which is simply one minus the rate of the code. In particular this tells us that the average entropy is always equal to the rate of the code. A code is said to be capacity achieving if there is some function
which is simply one minus the rate of the code. In particular this tells us that the average entropy is always equal to the rate of the code. A code is said to be capacity achieving if there is some function  that goes to zero with
that goes to zero with  such that
such that  whenever
whenever  . The area law immediately implies that in this case it must be that is close to one when
. The area law immediately implies that in this case it must be that is close to one when  (since otherwise the total integral would be smaller than
(since otherwise the total integral would be smaller than  ), and hence a code is capacity achieving if and only if the function has a threshold behavior. (See figure below).
), and hence a code is capacity achieving if and only if the function has a threshold behavior. (See figure below).
The paper above uses this observation to show that the Reed Muller code is capacity achieving for this binary erasure channel. The only property they use is the symmetry of this code which means that for this code we might as well have defined with some fixed coordinate (e.g., the first one). In this case, using linearity, we can see that for every erasure pattern  on the coordinates
on the coordinates 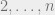 the entropy of
the entropy of 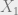 given
given 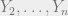 is a Boolean monotone function of . (Booleanity follows because in a linear subspace the entropy of the remaining coordinate is either zero or one; monotonicity follows because in the erasure channel erasing more coordinates cannot help you decode.) One can then use the papers of Friedgut or Friedgut-Kalai to establish such a property. (The Reed-Muller code has an additional stronger property of double transitivity which allows to deduce that one can decode not just most coordinates but all coordinates with high probability when the fraction of errors is a smaller than the capacity.)
is a Boolean monotone function of . (Booleanity follows because in a linear subspace the entropy of the remaining coordinate is either zero or one; monotonicity follows because in the erasure channel erasing more coordinates cannot help you decode.) One can then use the papers of Friedgut or Friedgut-Kalai to establish such a property. (The Reed-Muller code has an additional stronger property of double transitivity which allows to deduce that one can decode not just most coordinates but all coordinates with high probability when the fraction of errors is a smaller than the capacity.)
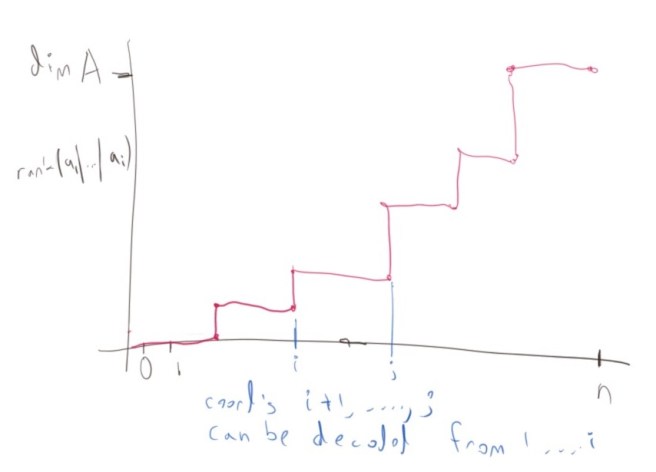
How do you prove this area law? The idea is simple. Because of linearity, we can think of the following setting: suppose we have the all zero codeword and we permute its coordinates randomly and reveal the first 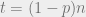 of them. Then the probability that the
of them. Then the probability that the  coordinate is determined to be zero as well is
coordinate is determined to be zero as well is 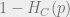 . Another way to say it is that if we permute the columns of the
. Another way to say it is that if we permute the columns of the  generating matrix
generating matrix  of randomly, then the probability that the column is independent from the first
of randomly, then the probability that the column is independent from the first  columns is
columns is  . In other words, if we keep track of the rank of the first columns, then at step the probability that the rank will increase by one is , but since we know that the rank of all columns is , it follows that
. In other words, if we keep track of the rank of the first columns, then at step the probability that the rank will increase by one is , but since we know that the rank of all columns is , it follows that  , which is what we wanted to prove. QED
, which is what we wanted to prove. QED
p.s. Thanks to Yuval Wigderson, whose senior thesis is a good source for these questions.

Great post (and great result).
Sanjeev