By Boaz Barak and Jarosław Błasiok
[Jarek gave a great informal exposition of this paper on Friday, and I asked him to make it into a blog post. My only knowledge of the paper is from Jarek’s explanations: my main contribution to this post was to delete some details and insert some inaccuracies –Boaz.]
A recent exciting paper of Ran Raz and Avishay Tal solved a longstanding problem in quantum complexity theory: the existence of an oracle under which the class 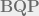

Rather than thinking about a single choice of an oracle, it turns out that it’s better to think of a distribution over oracles, and (for notational convenience) as a distribution 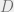
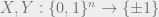
They show that:
- There is a quantum algorithm that can make one quantum query to each of these oracles, and using this distinguish with advantage at least
between the case that
and
are sampled from
for concreteness.)
- For every constant depth polynomial size circuit
on
inputs (where
), the probability that
on
sampled from
from the probability it outputs
Together 1 and 2 imply the main results by standard arguments.
The distribution
The distribution 
Specifically however, it is better to think about this distribution as follows:
- Sample
with the covariance matrix
where
is the
Hadamard matrix defined as
for every
. Another way to think about this is that
. Note that for any
,
.
- Then let
that has the expectation
. That is, for
, we choose
as a
random variable with expectation
and
as a
. If
or
are larger than
and each coordinate is a standard Normal then we truncate them appropriately, but because we set
this will only happen with probability
which we can treat as negligible and ignore this event from now on.
Distinguishing from uniform is easy for quantum algorithms
The heart of the proof is in the classical part, and so we will merely sketch why this problem is easy for quantum algorithms. A Quantum Algorithm that gets query access to 


The algorithm can then perform the Quantum Fourier Transform (in this case applying Hadamard to its qubits 

But in our case, 
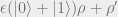
where 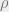

If we now perform the Hadamard operation on the first qubit and measure it, we will be about
is pseudorandom for AC0 circuits
We now come to the heart of the proof: showing that it is hard to distinguish 
At a high level, the proof shows that AC0 circuits can be approximated (to a certain extent) by very special kind of low degree polynomials – ones that are sparse in the sense that the L1 norm of their coefficients is not much larger than the L2 norm.
Anyway, we are getting ahead of ourselves. Let 
Main Theorem:

We will identify such a function 
![f(Z) = \sum_{S \subseteq [2N]} \hat{f}(S)\mathbb{E} \prod_{i\in S}Z_i](https://s0.wp.com/latex.php?latex=f%28Z%29+%3D+%5Csum_%7BS+%5Csubseteq+%5B2N%5D%7D+%5Chat%7Bf%7D%28S%29%5Cmathbb%7BE%7D+%5Cprod_%7Bi%5Cin+S%7DZ_i&bg=eeeeee&fg=666666&s=0&c=20201002)
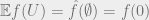
We start with the following simple observation: for every multilinear map 
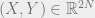


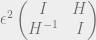
Hence the result will follow from the following result:
Main Lemma Let 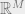




The 
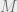

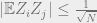
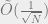
Note that the Main Lemma is of interest in its own right – it says that for a multivariate Gaussian to fool AC0, it is enough that the second moments sufficiently decay as long as the diagonal entries are moderately bounded away from 1. (However, for multivariate Gaussians, a bound on the second moments also implies decay of higher moments by Isserlis’ theorem.)
Proof of the Main Lemma
The Main Lemma is proved by a “Hybrid Argument”. (Related to arguments used by Chattopadhyay, Hatami, Hosseini and Lovett for constructing pseudorandom generators.) We will set 

where 
We write 
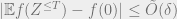
for every 

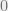
We can obtain the main lemma by summing up 
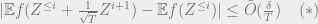
The main tool we will use to establish
L1 bound theorem: Let 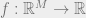
![z_0 \in [-1/2,+1/2]^M](https://s0.wp.com/latex.php?latex=z_0+%5Cin+%5B-1%2F2%2C%2B1%2F2%5D%5EM&bg=eeeeee&fg=666666&s=0&c=20201002)



![\sum_{U \subseteq [M], |U|=k} |\hat{g}(U)| \leq (2 \delta)^k (\log N)^{O(k)}](https://s0.wp.com/latex.php?latex=%5Csum_%7BU+%5Csubseteq+%5BM%5D%2C+%7CU%7C%3Dk%7D+%7C%5Chat%7Bg%7D%28U%29%7C+%5Cleq+%282+%5Cdelta%29%5Ek+%28%5Clog+N%29%5E%7BO%28k%29%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)

For 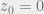
The L1 bound theorem implies 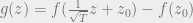

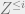

We can then bound the lefthand side of
the moment for 

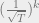

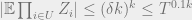


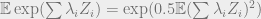

![\sum_{k \geq 1}\sum_{U \subseteq [M], |U|=k} |\hat{g}(U)| \mathbb{E} \prod_{i\in U}Z_i \leq \sum_{k \geq 1}(\tfrac{2}{\sqrt{T}})^k (\log N)^{O(k)} \mathbb{E} \prod_{i\in U}Z_i](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk+%5Cgeq+1%7D%5Csum_%7BU+%5Csubseteq+%5BM%5D%2C+%7CU%7C%3Dk%7D+%7C%5Chat%7Bg%7D%28U%29%7C+%5Cmathbb%7BE%7D+%5Cprod_%7Bi%5Cin+U%7DZ_i+%5Cleq+%5Csum_%7Bk+%5Cgeq+1%7D%28%5Ctfrac%7B2%7D%7B%5Csqrt%7BT%7D%7D%29%5Ek+%28%5Clog+N%29%5E%7BO%28k%29%7D+%5Cmathbb%7BE%7D+%5Cprod_%7Bi%5Cin+U%7DZ_i+&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof of the L1 bound theorem
We now show the proof of the L1 bound theorem. We say that function 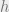


Claim: For every fixed ![z_0 \in [-1/2, 1/2]^M](https://s0.wp.com/latex.php?latex=z_0+%5Cin+%5B-1%2F2%2C+1%2F2%5D%5EM&bg=eeeeee&fg=666666&s=0&c=20201002)

Indeed, for given 
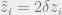


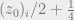



where 
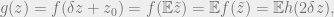
Now the L1 bound theorem follows by linearity of Fourier transform: for specific 
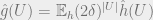
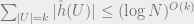
![\sum_{U \subset [M], |U| = k} |\hat{g}(U)| \leq \mathbb{E}_h \sum_{|U| = k} |\hat{h}(U)| (2\delta)^k \leq (2\delta)^k (\log N)^{O(k)}.](https://s0.wp.com/latex.php?latex=%5Csum_%7BU+%5Csubset+%5BM%5D%2C+%7CU%7C+%3D+k%7D+%7C%5Chat%7Bg%7D%28U%29%7C+%5Cleq+%5Cmathbb%7BE%7D_h+%5Csum_%7B%7CU%7C+%3D+k%7D+%7C%5Chat%7Bh%7D%28U%29%7C+%282%5Cdelta%29%5Ek+%5Cleq+%282%5Cdelta%29%5Ek+%28%5Clog+N%29%5E%7BO%28k%29%7D.+&bg=eeeeee&fg=666666&s=0&c=20201002)
which is what we needed to prove.
