Theoretical computer scientists love inequalities. After all, a great many of our papers involve showing either an upper bound or a lower bound on some quantity. So I thought I’d share some cool stuff I’ve learned this Friday in our reading group‘s talk by Zeev Dvir. This is based on my partial and vague recollection of Zeev’s talk, so please see the references in his paper with Hu (and a previous paper of Hardt and Moitra) for the complete (and correct) information. See also this blog post of James Lee.
The Brascamp–Lieb inequality is actually a shorthand for a broad family of inequalities generalizing the Holder Inequality, Young’s Inequality, the Loomis–Whitney inequality and many more. As Zeev put it, it probably generalizes any inequality you (or at least I) know about. Barthe gave an (alternative) proof of these inequalities, in the course of which he produced a magical lemma that turns out to be useful in many varying theoretical CS scenarios, from communication complexity to bounds for locally decodable codes, as well as for obtaining generalizations of the Sylvester-Gallai theorem in geometry.
One way to think about the Brascamp-Lieb inequality (as shown by Carlen and Cordero-Erausquin) is as generalizing the sub-additivity of entropy. We all know that given a random variable X over ℝd, H(X) ≤ H(X1) + ⋯ + H(Xd)
Where Xi is the ith coordinate of X. Now suppose that we let 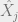

The Brascamp-Lieb inequality can be thought of as asking for the most general form of such inequalities. Specifically, given an arbitrary linear map F : ℝd → ℝn, we can ask for what vector of numbers γ = (γ1, …, γn) it holds that
H(X) ≤ γ1H(F(X)1) + ⋯γnH(F(X)n) + C
for all random variables X where C is a constant independent of X (though can depend on F, γ).
The answer of Brascamp-Lieb is that this is the case if (and essentially only if) the vector γ can be written as a convex combination of vectors of the form 1S where S ⊆ [n] is a d-sized set such that the functions {Fi}i ∈ S are linearly independent. You can see that the two cases above are a special case of this condition (where it also turns out that C = 0). (There is an even more general form where each 
The heart of the proof (if I remember Zeev’s explanations correctly) is to show that the worst-case for such an inequality is always when the variables F(X)1, …, F(X)n are a Gaussian process, that is X is some kind of a multivariate Gaussian distribution. Once this is show, one can phrase computing the supremum of C as a convex optimization problem over the parameters of this Gaussian distribution and then prove some bound on it.
For proving Brascamp-Lieb it is sufficient to simply bound C, but it turns out that the parameters that achieve the optimum C as a function of F and γ, have a very interesting property. Since the derivative of the objective function at this point must be zero, some algebraic manipulations show that one can obtain from them an invertible linear transofmation G such that
∑γiG(Fi)G(Fi)⊤/∥G(Fi)∥2 = I (*)
where I is the identity map on ℝd and Fi is the d-dimensional vector corresponding to the ith coordinate of F. The condition (*) looks somewhat mysterious, but one way to think about it is that it means that after a change of basis and rescaling so that each Fi is a unit vector, we can make the vectors F1, …, Fn be “evenly spread out” in ℝd in the sense that no direction is favored over any other one.
This turns out to be useful in some surprising contexts. For example, the notion of sign rank of a matrix is very important in several communication complexity applications. The sign rank of a matrix A ∈ { ± 1}n2 is the minimum rank of a matrix B such that sign(Bi, j) = Ai, j for every i, j. Clearly the sign rank might be much smaller than the rank, and proving that a matrix has large sign rank is a non-trivial matter. Nevertheless Forster managed to prove the following theorem:
Forster’s Theorem: The sign rank of A is at least n/∥A∥ where ∥A∥ is the spectral norm of A.
Which in particular gave a highly non trivial lower bound of 
The proof is easy given the above corollary (*). (Forster wasn’t aware of Barthe’s work, and as far as I know, the connection between the two works was first discovered by Moritz Hardt.) Suppose that there exists B of rank d such that sign(Bi, j) = Ai, j for every i, j. Then we can write Bi, j = 〈ui, vj〉for some vectors u1, …, un, v1, …, vn ∈ ℝd. By making a tiny perturbation, we can assume that for every subset S ⊆ [n] the vectors {ui}i ∈ S are linearly independent and hence in particular the vector γ = (d/n, …, d/n) can be expressed as a convex combination of the vectors of the form 1S, and hence in particular we get that after applying some change of basis and rescaling (which will not affect the sign of 〈ui, vj〉 ) we can assume without loss of generality that every ui,vj is a unit vector and moreover 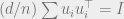
Now note that under our assumption Bi, jAi, j = |Bi, j| and hence

The last inequality follows from the fact that for every two matrices A, B, A ⋅ B ≤ ∑|λiσi|≤ max{λi}∑|σi|, where the λi‘s and σi‘s are the singular values of A and B respectively. We then use the fact that ∥A∥ = max{λi} and in B at most d of those are nonzero and hence by Cauchy-Schwarz 

or n/∥A∥ ≤ d as we wanted.

I had not been aware of the name Brascamp–Lieb inequality previously. A particular instance of this inequality was very useful in my work with Eyal Lubetzky on computing large deviation rates for triangle counts in random graphs (see Lemma 1 in https://yufeizhao.wordpress.com/2012/10/28/replica-symmetry/ for the specific inequality)
We had attributed the generalized Holder’s inequality to Finner (1992) https://projecteuclid.org/euclid.aop/1176989534
Thank you Yufei! I didn’t know about this work and it looks quite interesting.
This inequality seems to have been rediscovered in many communities which is why I thought a blog post could be useful, though I don’t know much about this history. Perhaps Moritz Hardt (who knows about these things more than me and has an excellent blog) will decide to write a post about this some day?
BTW one point which I didn’t get into but seems like an obvious question to me given my recent interests, is whether those inequalities can be proven via a sum of squares proof with degree depending only on and in particular if this degree is small when the entries of
and in particular if this degree is small when the entries of  are inverses of small integers.
are inverses of small integers.
Nice post, Boaz! As a side note, let me mention that Barthe in fact proves, with one short and elegant argument using the Brenier map, both the Brescamp-Lieb inequalities (BL) and the reverse Brescamp-Lieb inequalities (RBL). So, with one proof you get both Holder and many generalizations, and also Prekopa-Leindler (and therefore Brunn-Minkowski and isoperimetry) and many generalizations. And in both cases the tight constants are given by Gaussian functions. If there is a Master Theorem of functional and geometric inequalities, this is it.
Let me mention something which has been bothering me with how the scaling result (for any vectors in general position in
in general position in 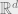 can there exists a linear map so that
can there exists a linear map so that 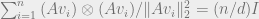 ), or at least its proof using convex programming, has been attributed to Barthe in recent TCS papers. For one thing, while Barthe analyzes the same convex program (it gives the constant factors in both BL and RBL), he does not prove the scaling result itself, as far as I can tell. He could have done that, and reduced his analysis to the “geometric” special case of BL and RBL, but his presentation is different. For another, a more general result about scaling PSD matrices (the result above is the special case for rank one matrices) was proved by Gurvits and Samorodnitsky in their work on approximating mixed discriminants and mixed volumes http://link.springer.com/article/10.1007%2Fs00454-001-0083-2. Their proof is exactly the one via convex programming attributed to Barthe (or rather its higher-rank generalization): look at section 3 of their paper. And the conference version of their paper is from STOC 2000, which is even before Forster’s paper, although Forster seems to not have been aware of it.
), or at least its proof using convex programming, has been attributed to Barthe in recent TCS papers. For one thing, while Barthe analyzes the same convex program (it gives the constant factors in both BL and RBL), he does not prove the scaling result itself, as far as I can tell. He could have done that, and reduced his analysis to the “geometric” special case of BL and RBL, but his presentation is different. For another, a more general result about scaling PSD matrices (the result above is the special case for rank one matrices) was proved by Gurvits and Samorodnitsky in their work on approximating mixed discriminants and mixed volumes http://link.springer.com/article/10.1007%2Fs00454-001-0083-2. Their proof is exactly the one via convex programming attributed to Barthe (or rather its higher-rank generalization): look at section 3 of their paper. And the conference version of their paper is from STOC 2000, which is even before Forster’s paper, although Forster seems to not have been aware of it.
BTW I am calling this a scaling result, because it is analogous to, and in fact generalizes, non-negative matrix scaling (the problem of scaling the rows and columns of a non-negative matrix to make it doubly stochastic). How to do matrix scaling via convex programming was known already in the 90s.