In an undergraduate algorithms class we learn that an algorithm is a high level way to describe a computer program. The running time of the algorithm is the number of operations it takes on inputs of a particular size- the smaller the better. So, as even Barack Obama knows, if you implement Quick-Sort, with its running time of 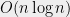
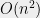
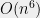
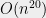

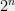
So why do we care about getting asymptotically good algorithms? Every TCS graduate student should be able to recite the “party line” answer that it has happened again and again that once a problem has been shown to be in polynomial time, people managed to come up with algorithms with small exponents (e.g. quadratic) and reasonable leading constants. There is certainly some truth to that (see for example the case of the Ellipsoid and Interior Point algorithms for linear programming) but is there an underlying reason for this pattern, or is it simply a collection of historical accidents?
Paul Erdős envisioned that “God” holds a book with the most elegant proof for every mathematical theorem. In a famous quote he said that “you don’t have to believe in God, but you have to believe in the Book”. Similarly, one can envision a book with the “best” (most efficient, elegant, “right”) algorithms for every computational problem. The 


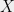


The same intuition holds for hardness results as well. The famous PCP theorem can be thought of as a reduction from the task of exactly solving the problem SAT to the task of solving it approximately. But if you apply the original PCP reduction to the smallest known hard instances of SAT (which have several hundred variables) the resulting instance would be too large to fit in even the NSA’s computers. What is the meaning of such a reduction? This issue also arises in cryptography. As some people like to point out, often when you reduce the security of a cryptographic scheme 

Another way to think of this is that the goal of a theory paper is not to solve a particular problem, but to illustrate an idea- discover a “paragraph from the book” if you will. The main reason we care about measures such as asymptotic running time or approximation factor is not due to their own importance but because they serve to “keep us honest” and provide targets that we won’t be able to reach without generating new ideas that can later be useful in many other contexts.
Erdős’s quote holds true for theoretical computer scientists as well. Just as physicists need to believe in a “book” of the laws of nature to make inferences based on past observations, the Book of algorithms is what makes TCS more than a loose collection of unrelated facts. (For example, this is why in his wonderful essay, Russell Impagliazzo was right to neglect some “non-Book” scenarios such as 

[Updated 2/25 with some minor rephrasing]

erdos, one of the greats, nobody like him, ahead of his time in various ways and some of his research seems to have an uncanny 20-20 hindsight significance in TCS. see also erdos 100, tribute to brilliant contrarian
Nice post. Gives you some general high level orientation of things in complexity.
Boaz, you might be interested in community suggestions for other entries in the book.
Thank you for the pointer. I think some people take the “Book” metaphor slightly differently than what I mean above. I see the “Book” as the mathematical analog to Occam’s Razor – we have certain observations, for example that a problem is NP hard or that a problem has a non-trivial algorithm, and believing in the Book corresponds to believing that there is a beautiful/economical explanation for these observations – i.e., that the optimal algorithm is elegant and simple. (Of course “elegance” and “simplicity” are not well defined terms, and an important part of our progress in science can be thought of as “learning God’s measures for elegance”; for example as people got used to quantum mechanics and understand it better they started appreciating its mathematical elegance even if it wasn’t immediately apparent.)
The Book algorithm is not the first paper on the subject but the last one. So to me results such as the AKS primality testing or Gentry’s Fully Homomorphic Encryption are amazing breakthroughs but they are *not* the Book algorithms.
I didn’t see your reply till just now.
In my first reading of your post, I interpreted your notion of an entry in the Book as a view into “explanations from the Book” rather than the strict notion of “proofs from the Book”. Although, I imagine that the distinction between explanation and proof is a debatable one, especially since a proof that one imagines as being in the Book should have explanatory value.
The cstheory.stackexchange entries are quite different, with the notion of algorithms from the Book, and a lot of the entries were of the succinct and clever variety, but not necessarily of the type that exposed a fundamental underlying structure.
Insertion-Sort is O(n^2). I’m pretty sure Bubble-Sort is a bit worse than that.
The difference in the running time of bubble sort and insertion sort is a multiplicative constant (2, I believe), and so both run in time O(n^2)
One remark on this nice post: Of course, the asymptotic lens is a very powerful paradigm, both in mathematics and in the theory of algorithms. One typical flaw in application of asymptotic thinking is in cases where there are more than one parameter. With certain problems depending (say) on two parameters m and n there are cases where mainly the asymptotic behavior for fixed m and n tending to infinity is studied, and that insights for this regime are interpreted too widely. It is useful to remember that with several variables there could be many interesting mutual asymptotic behaviors and when you consider related questions or even applications it is a subtle issue to find the relevant asymptotics.