I love sports, at least watching it. I could be tempted to follow any competition in any sport (with the obvious exceptions of baseball, cricket and golf). Now that the London Olympic games are almost forgotten and the world cup a full year and a half away (576 days to be precise) I want to discuss tennis, some of its recent deficiencies and how analysis of boolean functions can save it.
One of the characteristics of tennis lately is that it is very predictable. Basically, for a long time there were two players that dominated the sport, with one player joining this elite group last year (ok, 1.5 if you are British). In the past 7 years, the 28 grand slam titles are divided such: Federer: 11, Nadal: 10, Djokovic: 5 and Del Potro and Murray have one each. Expanding the scope, out of the 56 spots in the finals, Fed, Nadal and the Djoker occupy 42. The gap between the elite group and the rest of the pack is especially evident when observing head to head comparisons. Andy Roddick, who spent almost all his career at the top 10 has an abysmal 3:21 record against Federer. David Ferrer, another reliable top 8 player is 0:15 against Federer. This predictability undercuts the drama in sports and makes it less interesting.
My admittedly not data driven intuition is that this was not the case before the Federer era. So what’s going on? One possible reason is the extraordinary talent of the current set of elite players. After all, one should expect some separation between the samples at the very tail of the talent distribution. Perhaps the current group of top players is simply better, relatively speaking, than the top group of yore. This explanation, though plausible, just doesn’t sound right. The keen followers of the sport are aware how incredibly talented the ‘second tier’ players are. Also, it seems as though the results are too predictable also when looking further down the ranking. See for instance the complaints here.
Another possible explanation, which I like better, is that the advances in equipment and training methods increased the relative reward a player gets from a given advantage in talent. Specifically, I think, the new strings allow players to be extremely consistent, and thus reduce the noise in the point allocation. This theory echoes a common theme in labor economics, where the rise in income inequality is explained by claiming that advances in technology increase the disparity in productivity between high and low skilled workers. (See for instance http://www.nber.org/reporter/winter03/technologyandinequality.html, I thank Daniele Paserman for pointing out this connection). If this is indeed the case, then this phenomenon is probably with us to stay. What to do?
Well, one option is to change the way the game is played. In this and the next posts we will see that a few rule changes can dramatically change the outcome. But first lets try and reason about the definition of games in this context.
What’s in a game?
Well, a game is just a series of points played, each point is assigned to the player who won it. Let’s say the game consists of a fixed number of 
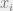

Let’s assume that the outcome of each point played is independently sampled with probability 
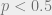


What do we require from
Firstly, we require 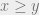


A second requirement is that 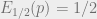
A third requirement is imposed in order to limit ourselves to games where all points are at least a-proiri meaningful, so that we rule out simple solutions like having the outcome be determined by a single point. We want the function to be transitive. This is a loose notion of symmetry which formally means that for every two indices 


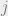

Given these constraints we want the game to be interesting: we want the outcome to be as ‘undetermined’ as possible. In our setting what we want is to examine the case where 
Which functions are used in popular games?
– Foosball: majority (best of 9)
– Table Tennis: majority of majorities (best of 7 sets)
– Tennis: majority of majority of majorities (game, set, match)
So which one is the best and can we have an even better way of playing these games?
When 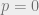
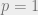

The value of 
Basically we are interested in the ‘threshold properties’ of the function. There is a rich and beautiful theory on this topic, which I unfortunately know and understand way too little. The answers to questions above though are quite accessable and would be given in the next post.

One thought on “Tennis for the People”