In my first post on this blog I would like to expand its range of topics to applied cryptography and share some interesting new findings that so far have not been reported anywhere else except a Eurocrypt’12 rump session talk.
On Valentine’s Day earlier this year, the paper with a somewhat enigmatic title “Ron was wrong, Whit is right” appeared as a pre-print on IACR’s website. Of course, it did not allege that Ron (Rivest) had done something horribly wrong that Whit (Diffie) hadn’t, but rather that some people who generated RSA keys messed up badly. The authors of the paper, Lenstra et al., came out with a surprising announcement that they managed to factor many RSA moduli collected from the web.
Factoring a single 1024-bit RSA number is hard, well beyond resources of a single research group (the public world-record was factoring a 768-bit number in 2010, which required about 2000 CPU core-years; factoring a 1024-bit number was estimated to be roughly 1000 times harder). On the other hand, factoring two RSA moduli is easy if they share a prime factor, by computing their greatest common divisor.
Lenstra et al. discovered that more than ten thousand RSA moduli collected from several sources (mostly X.509 certificates from the web and PGP keys) did share a prime factor with at least one other modulus in that dataset, which allows anyone, not just the owners of the certificates, to factor those numbers.
The news were widely reported by the media including The New York Times, but I especially like Nadia Heninger’s reaction on the Freedom to Tinker blog. She put some of the sensationalists claims from the press to rest in her post with a self-explanatory name “New research: There’s no need to panic over factorable keys—just mind your Ps and Qs.” The paper was also subject of some friendly banter by Whitfield Diffie, Ron Rivest, and Adi Shamir on the Cryptographers’ Panel from the RSA Conference, which can be watched here (min 2–10).
The original Lenstra et al. paper was careful not to disclose many details essential to interpreting or reproducing their findings in order to protect the compromised systems. It naturally piqued curiosity of my colleagues, who decided to replicate results of the paper on a dataset available to us (instance of the Streisand effect?). We also wanted to verify that Microsoft’s own keys were not in the factorizable set.
What follows is a summary of a joint work of Martín Abadi, Andrew Birrell, Ted Wobber, myself (Ilya Mironov), and several others in Microsoft. Since vendors and administrators of vulnerable systems have been notified by the EPFL and UCSD groups, we don’t think that this publication puts anyone at risk. The first part of the post covers the algorithm for doing batch GCD computation, and in the second we revisit some theories that were put forward to explain the phenomenon of repeat primes. We will also describe a curious fingerprinting property of the OpenSSL library, whose discovery was collateral to our main effort.
Let us first set up some notation. Let 
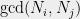
To give you a sense of the scale of this operation, here are some concrete numbers. We had access to a dataset (a snapshot of the EFF SSL Observatory from mid-2010) with approximately 4.4M distinct RSA keys, almost all of which had length 1024 or 2048 bits. Computing GCD of two 1024-bit numbers takes about 



Taking a cue from Nadia’s post, we compute a product of all numbers 

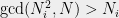
Thus the problem decomposes into two steps. First, we compute the product of all moduli, whose size is going to be more than 650 MBytes. Having done that, we will compute GCD of this giant number with all
Phase I. In a world where the best available multiplication routine is quadratic (i.e., multiplying two numbers of length 
The crucial observation here is that while multiplication is associative, its running time isn’t. In other words, computing the product 


To leverage FFT multiplication to maximal effect, we’d like to be multiplying balanced inputs (i.e., of roughly equal sizes) whenever possible. It motivates organizing the computation in a tree, naturally called the product tree. For history going as far back as 1958 and many applications of product trees in computational number theory see Dan Bernstein’s survey “Fast Multiplication and Its Applications”. Example of a product tree on eight numbers is given below.

Since FFT multiplication of two 







Even though the FFT implementation in the GMP library does not kick in until the numbers become as large as 500K bits, this is exactly where a slower quadratic algorithm would have spent the bulk of its running time.
Phase II. Once we computed the giant product 

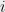
We observe first that 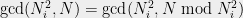
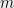

We will use the simple equation 

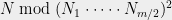
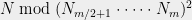

This method of computation is called the remainder tree, and illustrated above. We again refer to Dan Bernstein’s survey for its applications and bibliography.
Phase III. After the remainder tree is constructed, we may compute 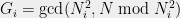




Since modular reduction takes time roughly proportional to multiplication, the running time of Phase II is asymptotically the same as that of Phase I. Constants matter. In our implementation Phase I takes about 20 minutes, Phase II about 10 hours, and Phase III a few seconds on a single core. The main implementation challenge was finding a machine with enough memory to fit the product tree in RAM (the memory usage peaked at 29GBytes), although a more careful organization of the computation could reduce memory overhead to a constant factor over the size of the input.
Compare it with 5 CPU core-years required by the pair-wise GCD computation, and next time you hear that FFT multiplication is irrelevant to applications (“stunt” computations, such as computing 
We implemented and ran the algorithm described above on our collection of certificates. As expected, we found many factorizable moduli (none was Microsoft’s), confirming the main findings of Lenstra et al. Our dataset was somewhat smaller compared to Lenstra et al.’s but close enough to gain some insight into underlying causes of this vulnerability. In the second installment of this post, we will put to test some plausible explanations for the curious case of repeating primes and offer some of our own.

Thanks so much Ilya for putting together this report. The description was immensely illuminating and refreshing to a non-crypto reader like me. This was 15 minutes very well spent for me today.
May I ask 2 questions please: What is the base for the log in the used equations ? and is log^2m equivalent to (log m)^2 ?
Since logs in this post appear only inside asymptotical expressions, the base does not matter as long as it is constant. You may use base 2, since in our implementation the branching factor of the product and remainder tree is 2. To answer your second question, no log 2m means log(2m).