Part II. For Part I see here.
Having largely reproduced the main results of the Lenstra et al. paper, the next research question became identifying the root cause or causes of this vulnerability. There was no shortage of explanations put forward shortly after the paper was released, and we were able to critically examine some of them.
What we found. Before we delve into mathematics of RSA, let us review the set of certificates with factorable moduli. All in all we identified 10,865 factorable moduli, all but 215 of which are from self-signed certificates. Just one certificate could be trusted by your browser, and it has long expired. All numbers below refer to counts of distinct moduli, some of which may (and do) appear in many certificates. A casual inspection of the issuers of the certificates with factorable moduli reveals that they fall into two large categories. 70% of these moduli appear in certificates that share the same naming convention and are associated with a similar type of devices from a single manufacturer. The other 30% is a very diverse lot and, although there are some identifiable families of similarly named certificates, none accounts for more than 25% of the rest. For example, a few dozen of certificates from the second group appear to have been collected from Internet-connected printers or photocopiers.
Is RSA secure? Does the fault lie with the RSA algorithm, which the title of the paper has implied? Can it be that when sufficiently many people generate RSA moduli independently of each other, collisions are due to happen?
Recall that the RSA modulo is a product of two primes. Modern guidelines recommend choosing two random primes of the same length, half the size of the modulus. The modulus should be at least 1024-bits long, or better yet, 2048 bits. Since all but one factorable moduli have length 1024 bits or less (despite comprising less than 80% of the dataset), it might suggest that a short modulus length has something to do with the problem. Simple computation shows that it is not the case.
The density of primes of length 512 bits is approximately 
![{[1,2^{512}]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2C2%5E%7B512%7D%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)



Our conclusion: the possibility of a random collision between primes can be ignored.
Gaps in primes? Pip, who is otherwise known as Dick Lipton and Ken Regan’s alter ego (or alteri nos, in plural?), plausible conjectured that a common method for sampling primes goes something like this:
- Generate random odd
of length
bits.
- If
, go to 2.
(Actually, Pip proposed using 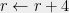
This procedure results in a non-uniform distribution over primes of a fixed length. It is immediate that any prime is output with probability proportional to the length of the interval that separates it from the previous prime. Can this non-uniformity be the reason why there are collisions between primes?
Let’s estimate the power of this effect. Let 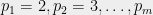
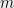
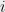
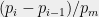
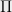
![\displaystyle \Pr_{a,b\leftarrow \Pi}[a=b]=\sum_{i=1}^m \Pr_{a\leftarrow \Pi}[a=p_i]\cdot\Pr_{b\leftarrow \Pi}[b=p_i]=\sum_{i=1}^m \frac{(p_i-p_{i-1})^2}{p^2_m}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr_%7Ba%2Cb%5Cleftarrow+%5CPi%7D%5Ba%3Db%5D%3D%5Csum_%7Bi%3D1%7D%5Em+%5CPr_%7Ba%5Cleftarrow+%5CPi%7D%5Ba%3Dp_i%5D%5Ccdot%5CPr_%7Bb%5Cleftarrow+%5CPi%7D%5Bb%3Dp_i%5D%3D%5Csum_%7Bi%3D1%7D%5Em+%5Cfrac%7B%28p_i-p_%7Bi-1%7D%29%5E2%7D%7Bp%5E2_m%7D.+&bg=eeeeee&fg=000000&s=0&c=20201002)
Given the probability of a single collision, the expected number of collisions among 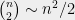
If primes were spaced uniformly through the interval, then the probability of a single collision would be equal to 
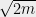
Primes are not uniformly spaced, and gaps, i.e., large intervals between primes, do happen (see the page that lists some record gaps).
The strongest (conditional) bound on the sum of the squared gaps is due to Atle Selberg, eminent Norwegian-American mathematician, recognized with the Fields Medal and the Wolf Prize. Assuming the Riemann Hypothesis he proved that
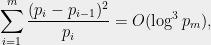
which translates into the following bound on the probability of collision (using the well-known fact that 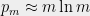
![\displaystyle \Pr_{a,b\leftarrow \Pi}[a=b]=O\left(\frac{\log^3 p_m}{p_m}\right)=O\left(\frac{\log^2 m\log \log^3 m}m\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr_%7Ba%2Cb%5Cleftarrow+%5CPi%7D%5Ba%3Db%5D%3DO%5Cleft%28%5Cfrac%7B%5Clog%5E3+p_m%7D%7Bp_m%7D%5Cright%29%3DO%5Cleft%28%5Cfrac%7B%5Clog%5E2+m%5Clog+%5Clog%5E3+m%7Dm%5Cright%29.+&bg=eeeeee&fg=000000&s=0&c=20201002)
Aside: The paper by Atle Selberg appeared in a Norwegian journal (a MathSciNet review with the result statement is available). I can only imagine what prevented Selberg from publishing in a journal with wider circulation in 1943.
The Selberg bound means that asymptotically the effect of gaps between primes can increase the number of collisions only by a factor of 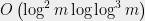
Our verdict: Biased distribution due to gaps in primes is not sufficient to explain collisions.
So, what’s the root of the vulnerability? If the probability of collision between primes numbers independently sampled from the uniform distribution, or even a slightly biased one, is negligible, why do we see collisions in practice? The only plausible explanation is that the numbers are not sampled independently. If the random choices are correlated or simply identical, then the outputs of the sampling procedures will collide.
This is a programming, not mathematical error—if one fails to initialize an excellent source of prime numbers with sufficient entropy, then two independent calls into this source will result in the same output if the “random” bits collide.
Generating the same RSA modulus on different devices would still be a security vulnerability albeit not as dramatic as factoring it by a third party. The reason why this process leads to the factoring attack is that some entropy is injected in between generation of prime factors (nicely explained with pseudo-code in Heninger’s post).
One error or many? If a likely cause of the vulnerability is a poor choice of the source of randomness, it becomes possible to trace it to particular libraries or systems that carry the flawed code.
Referring to sources of collisions, in the video from The Cryptographers’ Panel, Whitfield Diffie says that “if we find out what the sources of these random number generators are, we might just find that there is one bad one”. Can we, by looking at the certificates, decide whether there is a single or many bad random number generators out there?
Recall that factorable moduli can be classified into two large groups: one harvested from devices made by a single hardware manufacturer and all the rest that don’t have much in common. Let’s call the second group the Zoo.
Can the certificates from the Zoo be partitioned into some meaningful classes? There is some clustering in their validity dates but not enough to have any explanatory value… Let’s test whether their prime factors are safe, i.e., have form 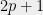
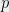
What an interesting property! Safe primes would have it, but most of these numbers are not safe. Some standards (such as ANSI X9.31) require strong primes, which implies that 
The answer is that the most popular library for generating prime numbers is the responsible party. OpenSSL has been ported to virtually all operating systems and underlies many products (including Adobe Acrobat, Apache, BIND, just from the beginning of the alphabet).
If we look at the OpenSSL procedure for sampling primes, we first notice that it is based on a perfectly reasonable algorithm for sampling safe primes. In pseudocode it looks roughly like this:
- Generate random odd
- while(
is divisible by any
)
.
- Use Miller-Rabin test to check whether
is prime. If not, go to 1.
- Use Miller-Rabin test to check whether
- Output
(OpenSSL contains a hardcoded table of the first 2048 prime numbers 
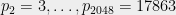
To generate RSA moduli that don’t need to be safe primes, which is its default choice, OpenSSL does something interesting. It applies the above procedure, skipping the third step.
- Generate random odd
- while(
Use Miller-Rabin test to check whether- Use Miller-Rabin test to check whether
- Output
Notice that the second step is intact: it will filter out numbers that are not equal to 1 modulo 
We want to emphasize that the property of “OpenSSL” prime numbers, i.e., not being equal to 1 modulo the first 2048 prime numbers, is not a security vulnerability. It is a fingerprint. A random 512-bit prime number has this property with probability
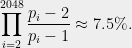
It means that the OpenSSL procedure for sampling primes reduces their pool, but not enough to increase collision probability or to permit some special-purpose factoring algorithm (if one existed, it would be effective on 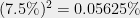
On the other hand, it allows us to say with very high degree of confidence that all but 120 certificates from the Zoo were produced by OpenSSL (3046 all together; if we include certificates that could have been produced by an 8-bit version of OpenSSL that used the 54 smallest prime numbers instead of 2048, the number of non-OpenSSL certificates further reduces to 100).
If our conclusion that the Zoo moduli were produced with OpenSSL relies on a probabilistic argument, we can categorically rule out OpenSSL as the source of the larger set of certificates, associated with a single hardware vendor. When we reached out to the vendor for validation, we were able to confirm that a different, proprietary software stack was used to generate those certificates. As expected, the underlying cause of the problem was insufficient entropy, the issue that had already been addressed by the vendor (it also used the OpenSSL library in other product lines, with similar problems). That settles negatively Diffie’s hypothesis that there is only one flawed implementation of RSA key generation mechanism.
When does OpenSSL use a random number generator with poor entropy? It is often the case that devices generate certificates as part of their boot sequence. Unless the generator has been seeded with a good source of entropy, its output is going to be predictable or simply fixed. Until version 0.9.7 (released on Dec 31, 2002) OpenSSL relied exclusively on the /dev/urandom source, which by its very definition is non-blocking. If it does not have enough entropy, it will keep churning out pseudo-random numbers possibly of very poor quality in terms of their unpredictability or uniqueness. FreeBSD prior to version 5 posed its own problem, since its /dev/random source silently redirected to /dev/urandom.
Finally, we examine Adi Shamir’s tongue-in-cheek conjecture from the same Cryptographers’ Panel. He suggested that the phenomenon of colliding primes, where 10,000 collisions are observed from among 2
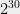
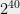
Conclusion. Weak RSA certificates occur fairly often and affect thousands of Internet-connected devices. We reject the notion that based on this evidence, RSA is fundamentally flawed or significantly less secure than schemes based on the discrete logarithm. The blame for existence of factorable certificates lies with devices that fail to seed the random number generator with sufficient entropy. Some unfortunate choices by the OpenSSL library didn’t help either. We also observe a new, previously undocumented property of OpenSSL-generated prime numbers, which allowed us to trace virtually all factorable moduli to just two sources: one hardware vendor’s proprietary code and the OpenSSL library.

As I already said in the post you quoted, OpenSSL add the current time in second BEFORE generating a new random number and not after.
Just look at the code of BN_rand :
bnrand function, line 142 in bn_rand.c :
time(&tim);
RAND_add(&tim,sizeof(tim),0.0);
[…]
if (RAND_bytes(buf, bytes) <= 0)
so I really don't see why they should share the same p if the key hasn't been generated at the exact same time (in seconds) or the clock is not initialized and the key is automatically generated at the first boot but I doubt of this …
(or it's a really old version of OpenSSL or a modified one)
“”exclusively on the /dev/urandom source, which by its very definition is non-blocking.””
only in Linux.
In sane operating systems, like FreeBSD, urandom provides high quality random numbers.
One property of a RSA prime is that it’s msb must set to 1 so although a 512 bit prime is 512 bits in length, only one half of the 512 bit space is used to generate primes. Not sure how that affects your calculations.
Good point, but it really does not affect the argument much. For instance, what is the density of primes in the [x, 2x] range? According to the prime number theorem, it is approximately 2x/ln(2x) – x/ln(x) ~ x/ln(2x)-(ln(2)*x)/(ln x)^2, which in the range of interest requires a very small adjustment to the probability of a random number from this range’s being prime ~1/ln(2x). The heuristic analysis of the OpenSSL algorithm is independent of the range from which the primes are sampled.