In this post, I am going to give you a simple, self-contained, and fruitful demonstration of a recently introduced proof technique called the method of interlacing families of polynomials, which was also mentioned in an earlier post. This method, which may be seen as an incarnation of the probabilistic method, is relevant in situations when you want to show that at least one matrix from some collection of matrices must have eigenvalues in a certain range. The basic methodology is to write down the characteristic polynomial of each matrix you care about, compute the average of all these polynomials (literally by averaging the coefficients), and then reason about the eigenvalues of the individual matrices by studying the zeros of the average polynomial. The relationship between the average polynomial and the individuals hinges on a phenomenon known as interlacing.
We will use the method to prove the following sharp variant of Bourgain and Tzafriri’s restricted invertibility theorem, which may be seen as a robust, quantitative version of the fact that every rank 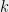
Theorem 1 Suppose
are vectors with
. Then for every
there is a subset
of size
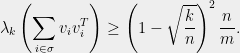
That is, any set of vectors 
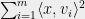

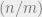
The original applications of Theorem 1 and its variants were mainly in Banach space theory and harmonic analysis. More recently, it was used in theoretical CS by Nikolov, Talwar, and Zhang in the contexts of differential privacy and discrepancy minimization. Another connection with TCS was discovered by Joel Tropp, who showed that the set 
In more concrete notation, the theorem says that every rectangular matrix 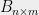
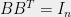

![{S\subset [m]}](https://s0.wp.com/latex.php?latex=%7BS%5Csubset+%5Bm%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)


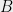
As I said earlier, the technique is based on studying the roots of averages of polynomials. In general, averaging polynomials coefficient-wise can do unpredictable things to the roots. For instance, the average of 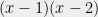
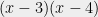

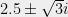
The main insight is that there are nonetheless many situations where averaging the coefficients of polynomials also has the effect of averaging each of the roots individually, and that it is possible to identify and exploit these situations. To speak about this concretely, we will need to give the roots names. There is no canonical way to do this for arbitrary polynomials, whose roots are just sets of points in the complex plane. However, when all the roots are real there is a natural ordering given by the real line; we will use this ordering to label the roots of a real-rooted polynomial 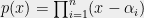
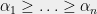
Interlacing
We will use the following classical notion to characterize precisely the good situations mentioned above.
Definition 2 (Interlacing) Let
be a degree
polynomial with all real roots
, and let
be degree
with all real roots
(ignoring
in the degree
Following Fisk, we denote this as
, to indicate that the largest root belongs to
If there is a single
, we say that they have a common interlacing.

It is an easy exercise that 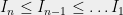

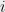

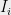
We now state the main theorem about averaging polynomials with common interlacings.
Theorem 3 Suppose
denote the
largest root of
be any distribution on
. If
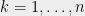
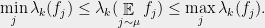
The proof of this theorem is a three line exercise. Since it is the crucial fact upon which the entire technique relies, I encourage you to find this proof for yourself (Hint: Apply the intermediate value theorem inside each interval

One of the nicest features of common interlacings is that their existence is equivalent to certain real-rootedness statements. Often, this characterization gives us a systematic way to argue that common interlacings exist, rather than having to rely on cleverness and pull them out of thin air. The following seems to have been discovered a number of times (for instance, Fell or Chudnovsky & Seymour); the proof of it included below assumes that the roots of a polynomial are continuous functions of its coefficients (which may be shown using elementary complex analysis).
Theorem 4 If
have real roots, then they have a common interlacing.
Proof: Since common interlacing is a pairwise condition, it suffices to handle the case of two polynomials 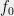
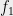

with ![{t\in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bt%5Cin+%5B0%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

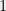
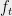
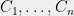
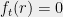

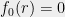
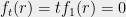

Characteristic Polynomials and Rank One Updates
A very natural and relevant example of interlacing polynomials comes from matrices. Recall that the characteristic polynomial of a matrix 
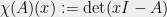
and that its roots are the eigenvalues of
Lemma 5 (Cauchy’s Interlacing Theorem) If
is a vector then

Proof: There are many ways to prove this, and it is a nice exercise. One way which I particularly like, and which will be relevant for the rest of this post, is to observe that
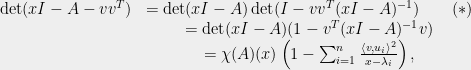
where 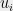

We are now in a position to do something nontrivial. Suppose 

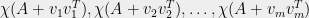
have a common interlacing, namely 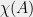

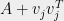
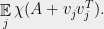
We can compute this polynomial using the calculation 

In general, this polynomial depends on the squared inner products 


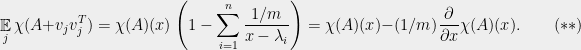
That is, adding a random rank one matrix in the isotropic case corresponds to subtracting off a multiple of the derivative from the characteristic polynomial. Note that there is no dependence on the vectors 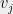
As a sanity check, if we apply the above deduction to 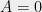

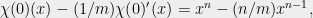
which is just 

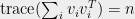
Differential Operators and Induction
The real power of the method comes from being able to apply it inductively to a sum of many independent random 
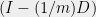
Lemma 6 (Properties of Differential Operators)
- If
is a random vector with
then
- If
.
- If
.

Proof: Part (1) was essentially shown in 

![{f=\chi[A]}](https://s0.wp.com/latex.php?latex=%7Bf%3D%5Cchi%5BA%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{(1-cD)f=\chi[A+vv^T]}](https://s0.wp.com/latex.php?latex=%7B%281-cD%29f%3D%5Cchi%5BA%2Bvv%5ET%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
For part (3), Theorem 3 tells us that all convex combinations 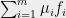
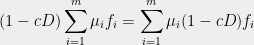
also have real roots. By Theorem 4, this means that the 
We are now ready to perform the main induction which will give us the proof of Theorem 1.
Lemma 7 Let
so that
, and let
be i.i.d. copies of
satisfying

Proof: For any partial assignment 

We will show that there exists a ![{j_{\ell+1}\in [m]}](https://s0.wp.com/latex.php?latex=%7Bj_%7B%5Cell%2B1%7D%5Cin+%5Bm%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
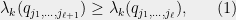
which by induction will complete the proof. Consider the matrix
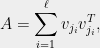
By Cauchy’s interlacing theorem 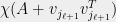

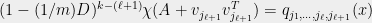
(by applying Lemma 6 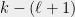
Bounding the Roots: Laguerre Polynomials
To finish the proof of Theorem 1, it suffices by Lemma 7 to prove a lower bound on the 
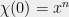

This looks like a nice polynomial, and we are free to use any method we like to bound its roots.
The easiest way is to observe that

where 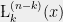
Lemma 8 (Roots of Laguerre Polynomials) The roots of the associated Laguerre polynomial
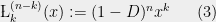
![{[n(1-\sqrt{k/n})^2,n(1+\sqrt{k/n})^2].}](https://s0.wp.com/latex.php?latex=%7B%5Bn%281-%5Csqrt%7Bk%2Fn%7D%29%5E2%2Cn%281%2B%5Csqrt%7Bk%2Fn%7D%29%5E2%5D.%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
It follows by Lemma 8 that 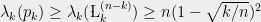
If you think that appealing to Laguerre polynomials was magical, it is also possible to prove the bound (3) from scratch in less than a page using the `barrier function’ argument from this paper, which is also intimately related to the formulas
Conclusion
The argument given here is a special case of a more general principle: that expected characteristic polynomials of certain random matrices can be expressed in terms of differential operators, which can then be used to establish the existence of the necessary common interlacings as well as to analyze the roots of the expected polynomials themselves. In the isotropic case of Bourgain-Tzafriri presented here, all of these objects can be chosen to be univariate polynomials. Morally, this is because the covariance matrices of all of the random vectors involved are multiples of the identity (which trivially commute with each other), and all of the characteristic polynomials involved are simple univariate linear transformations of each other (such a 
On the other hand, the proofs of Kadison-Singer and existence of Ramanujan graphs involve analyzing sums of independent rank one matrices which come from non-identically distributed distributions whose covariance matrices do not commute. At a high level, this is what creates the need to consider multivariate characteristic polynomials and differential operators, which are then analyzed using techniques from the theory of real stable polynomials.
Acknowledgments
Everything in this post is joint work with Adam Marcus and Dan Spielman. Thanks to Raghu Meka for helpful comments in the preparation of this post.
UPDATE: In response to Olaf’s comment below, here is how to see that the bound in the theorem is sharp.
The tight example is provided by random matrices. Let 


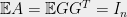
(1) If 
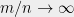
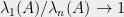
almost surely. Thus, if we take the 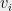
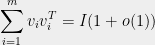
almost surely.
(2)If 
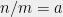
![{[(1-\sqrt{a})^2,(1+\sqrt{a})^2]}](https://s0.wp.com/latex.php?latex=%7B%5B%281-%5Csqrt%7Ba%7D%29%5E2%2C%281%2B%5Csqrt%7Ba%7D%29%5E2%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
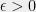
![\displaystyle \mathbb{P} [\lambda_{n}(A)>(1-\sqrt{a})^2+\epsilon]<\exp(-c(\epsilon)n^2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D+%5B%5Clambda_%7Bn%7D%28A%29%3E%281-%5Csqrt%7Ba%7D%29%5E2%2B%5Cepsilon%5D%3C%5Cexp%28-c%28%5Cepsilon%29n%5E2%29&bg=eeeeee&fg=000000&s=0&c=20201002)
for sufficiently large
Fact (2) implies that every 


with probability 
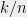

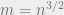


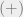


It would be nice to have an argument for finite

Dear Mr Srivastava,
You’ve claimed that your version of the restricted invertibility THM is sharp. Could You tell me for which k this result is sharp and how to see this.
Best regards,
Olaf Mordhorst
Dear Olaf,
That is an excellent question! I have added a section to the post, describing the sense in which the bound is sharp.
Best wishes,
Nikhil
Dear Nikhil,
Thank you for this post. It was never clear to me whether the dependence is optimal in the restricted invertibility principle. The argument you present here is very clear. By the way: A=GG^T without expectation. After equation (+), I think it should be with probability bigger than 1-\exp(-ck^2). Also the line just after should be \exp(c’k\log(m/k)).
Also did you try to get simultaneously a lower and upper bound for the singular values of the restricted matrix i.e. to get a well conditionned submatrix in the same sense of what is done here: http://arxiv.org/pdf/1212.0976v2.pdf
Best wishes,
Pierre
Thanks, Pierre! Fixed.
Your paper looks very interesting. I have not tried to get both bounds at once using this method for this regime of k, although in some sense that is what is done for k>n in the case of Kadison-Singer. The basic idea is to embed an upper and lower bound into a single matrix by using a direct sum. It would be interesting to see if your result can be obtained using polynomials.
Dear Nikhil,
Thank you very much for your comment. I’d failed to construct a counter example (by considering Hadamard basis), so your post helped me a lot. Maybe, one can construct a finite counter example by quantizing the gauss measure in your example (since the counter example does only depend on the distribution of the column vectors in G, which might be predictable for m>>n).
Bets wishes,
Olaf
This is a very nice blog post! It really helped me understand what’s going on with the method. I don’t think anyone will be confused by it for very long, but I think there is a small typo in equation (3), by the way.
Beautiful exposition, Nikhil! I’ve seen this explained a few times and this writeup nails it.
Dear Nikhil,
Thank you for the very nice exposition, it made the proof of Kadison-Singer much more intuitive for me. I have a question, if you have time to answer it: when you prove Theorem 1 from Lemma 7, the indices j_1,…, j_k might not be mutually distinct. Right? So in Theorem 1, we allow a vector v_i to appear several times in the last inequality?
Many thanks and best wishes,
Dorin
Hi Nikhil,
Nevermind the previous question, I read the notation wrongly. All clear now. Thanks again for the nice post!
Dorin