Guest post by Sam Hopkins
I just got back from dinner with some of the great speakers who will be at our TheoryFest workshop tomorrow afternoon on computational thresholds for average-case problems, and I am very excited for what’s coming! Since I didn’t get much chance to introduce the speakers in my last post, and not all of them are the “usual suspects” for a STOC workshop, I’d like to take a few paragraphs to do so here, and discuss a little further what they might speak about.
The talks will run the gamut from statistical physics to machine learning to good old theory of computing, and in particular will aim to address questions at their 3-wise intersection. This intersection is full of open problems which are both interesting and approachable. I hope to see lots of people there!
On to the speakers:
Florent Krzakala: Florent is a statistical physicist at the Sorbonne in Paris. For more than 10 years he has been one of the leaders in studying high-dimensional statistical inference and average-case computational problems through the lens of statistical physics.
One of my favorite lines Florent’s work was the construction (with several others) of random measurement matrices 
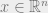


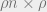

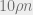
Lately, Florent tells me he has been interested in the physics of matrix factorization and completion problems, and of neural networks. Tomorrow he is going to discuss computational-versus-statistical gaps for a variety of high-dimensional inference problems, addressing the question of why polynomial-time inference algorithms don’t necessarily achieve information-theoretically-optimal results from a statistical physics perspective.
Nike Sun: Nike is a probabilist & computer scientist at UC Berkeley, before which she was the Schramm postdoctoral fellow at MIT and MSR. Many of you may know her from the tour de force work (joint with Jian Ding and Allan Sly) establishing the 
Her research spans many topics in probability, but tomorrow she is discussing random CSPs, on which she is among the world experts. In this area her work has made great steps in rigorous-izing the predictions of statistical physics regarding the geometry of the space of solutions to a random CSP instance. This geometry is rich: at some clause densities random CSPs seem to have well-connected spaces of solutions, and at others the solution spaces are shattered. In between are a wealth of phase transitions whose algorithmic implications remain poorly understood (read: a great source of open problems!).
Jacob Steinardt: Jacob is a graduating PhD student at Stanford, and a rising star in provable approaches to machine learning. One of his focuses of late has been design of algorithms for learning problems in the presence of untrustworthy data, model misspecification, and other challenges the real world imposes on the idealized learning settings we often see here at STOC.
His paper with Moses Charikar and Greg Valiant on list-learning has attracted a lot of attention and sparked several follow-up works at this year’s STOC. In that paper, Jacob and his coauthors realized that the problem of learning parameters of a distribution when only a tiny fraction (say 0.001 percent) of your samples come from that distribution provides a generalization of and useful perspective on many classic learning problems, like learning mixture models. (In the list learning setting, one aims to output a list of candidate parameters such that one of the sets of parameters is close to the parameters of the distribution you wanted to learn.)
Jacob’s work has explored the notion that polynomial-time tractability of learning problems is intimately related to robustness. A caricature: if any learning problem solvable in polynomial time can also be solved in polynomial time in the presence of some untrustworthy data, then polynomial-time algorithms cannot solve inference problems which are statistically impossible in the face of untrustworthy data. This offers an intriguing explanation for the existence of average-case/statistical problems which are unsolvable by polynomial-time algorithms, in spite of their information-theoretic (i.e. exponential-time) solvability.
I will also give a talk.
See you there!
Edit: correct some attributions.
