Guest post by Sam Hopkins
TheoryFest is in full swing in Los Angeles! There is lots to be written about the wealth of STOC talks, invited papers, keynotes, and (maybe most importantly) the excellent food hall across the street which is swarming with theorists and mathematicians. But for now I want to bring to your attention the workshops planned for Friday.
As always, the schedule is packed with interesting talks! There are workshops on major themes in theory, like
- deep learning
- fairness in algorithms
- recent constructions of extractors
- Vijay Vazirani’s birthday, and
- average-case problems and computational thresholds
Since I helped organize the last of these, let me say a bit about it.
Recently we have seen a surge of interest in algorithms and lower bounds for average-case problems. One driver of this surge has been theory’s increasing connection with machine learning, which has suggested a number of high-dimensional and noisy statistical inference problems to study. Another driver has been the substantial progress on long-standing problems regarding random instances—for example, a series of recent works proving many old conjectures on random k-SAT instances, and another series of works analyzing algorithms for community detection and recovery in very sparse random graphs.
A common theme in average-case computational problems is that their statistical difficulty (that is, whether they are solvable by any algorithm at all, regardless of running time) is not predictive of their algorithmic difficulty (that is, whether they are solvable by polynomial-time algorithms).
A now-standard example is the 

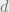




It turns out that so long as 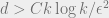
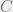
However, it is conjectured that this community recovery is possible in polynomial time if and only if (!!) 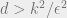

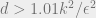
This kind of threshold phenomenon is ubiquitous for high-dimensional inference problems, and remains largely unexplained. Of course, we are used to algorithmic intractability! But the appearance of intractability for average-case problems seems not to be explained by worst-case theories of hardness (like NP-completeness). And very little is known about what features of an average-case problem are predictive of computational tractability, and which might predict intractability (while in the worst case we know that, say, NP-completeness is an excellent predictor of intractability). The sharpness of a threshold like 
We will have four talks, spanning algorithms and complexity, with (at least) four perspectives on computational thresholds for average-case problems and related matters. Florent Krzakala will lead off with a statistical-physics perspective on algorithms and hardness for matrix and tensor factorization problems. Nike Sun will give us a taste of the wild world of random constraint satisfaction problems. Jacob Steinhardt will talk about the relationship of outlier robustness and inaccurate/partial problem specification to efficient algorithms for statistical inference. Finally, I will survey some recent developments at the intersection of convex programming, the Sum of Squares method, and high-dimensional inference problems.
I hope to see you there!

One thought on “Workshops at TheoryFest (including shameless advertisement)”