Update: I made a bit of a mess in my original description of the technical details, which was based on my faulty memory from Laci’s talk a year ago at Harvard. See Laci’s and Harald’s posts for more technical information.
Laci Babai has posted an update on his graph isomorphism algorithm. While preparing a Bourbaki talk on the work Harald Helfgott found an error in the original running time analysis of one of the subroutines. Laci fixed the error but with running time that is quantitatively weaker than originally stated, namely 
This is a large quantitative difference, but I think makes very little actual difference for the (great) significance of this paper. It is tempting to judge theoretical computer science papers by the “headline result”, and hence be more impressed with an algorithm that improves 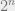


Improving quantitative parameters such as running time or approximation factor is very useful as intermediate challenge problems that force us to create new ideas, but ultimately the important contribution of a theoretical work is the ideas it introduces and not the actual numbers. In the context of algorithmic result, for me the best way to understand what a bound such as
Often, if you have a hardness result that (for example based on the exponential time hypothesis) shows that some problem (e.g., shortest codeword) cannot be solved faster than 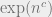



On the other hand, if you meet this bound “on your way down” in an algorithmic result, such as in this case, or in cases where for example you improve an 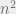

Of course it could be that for some problems this kind of bound is actually their inherent complexity and not simply the temporary state of our knowledge. Understanding whether and how “unnatural” complexity bounds can arise for natural problems is a very interesting problem in its own right.

Nice points. What do you think of the ideas in the latest Lipton/Regan blogpost, which they call “extended complexity neighbourhoods”?
In most cases I think of a quantity such as as not inherently being in the neighborhood of neither
as not inherently being in the neighborhood of neither  or
or  .
.
Rather it’s the complexity analog to a pool that has both water and ice. It’s not a steady state, and it helps to know the past in order to predict what equilibrium it will end up in.