This fall I will be teaching a graduate seminar on the Sum of Squares algorithm. Actually, it will be two “sister seminars”. In the Cambridge/Boston area, I (with possibly some guest lectures by Pablo Parrilo) will be teaching the course on Fridays 10am-1pm, alternating between Harvard and MIT. In Princeton, David Steurer and Pravesh Kothari will teach the course on Mondays.
If you are interested in attending the course, or even following it remotely, please see the course web page, and also sign up for its Piazza page (people without a Harvard email can use this form). David and I will be trying to write fairly complete lecture notes, which we will post on the website, and I might also post some summaries on this blog.
Here is the introduction for this course:
The terms “Algebra” and “Algorithm” both originate from the same person. Muhammad ibn Musa al Khwarizmi was a 9th century Persian mathematician, astronomer and geographer. The Latin translation of his books introduced the Hindu-Arabic decimal system to the western world. His book “The Compendious Book on Calculation by Completion and Balancing” also presented the first general solution for quadratic equations via the technique of “completing the square”. More than that, this book introduced the notion of solving general as opposed to specific equations by a sequence of manipulations such as subtracting or adding equal amounts. Al Khwarizmi called the latter operation al-jabr (“restoration” or “completion”), and this term gave rise to the word Algebra. The word Algorithm is derived from the Latin form of Al Khwarizmi’s name. (See The equation that couldn’t be solved by Mario Livio for much of this history.)

Muhammad ibn Musa al-Khwarizmi (from a 1983 Soviet Union stamp commemorating his 1200 birthday).
However, the solution of equations of degree larger than two took much longer time. Over the years, a great many ingenious people devoted significant effort to solving special cases of such equations. In the 14th century, the Italian mathematician Maestro Dardi of Pisa gave a classification of 198 types of cubic (i.e., degree 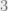

The solution for quintic formulas took another 250 years. Many great mathematicians including Descartes, Leibnitz, Lagrange, Euler, and Gauss worked on the problem of solving equations of degree five and higher, finding solutions for spcial cases but without
discovering a general formula. It took until the turn of the 19thcentury and the works of Ruffini, Galois and Abel to discover that in fact such a general formula for solving degree 5 or higher equations via combinations of the basic arithmetic formulas and taking roots does not exist. More than that, these works gave rise to a precise characterization of which equations are solvable and thus led to the birth of group theory.
Today, solving an equation such as 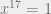
Let us fast-forward to present days, where the design of algorithms is another exciting field that requires a significant amount of creativity. The Algorithms textbook of Cormen et al has 35 chapters, 156 sections, and 1312 pages, dwarfing even Dardi’s tome on the 198 types of cubic and quartic equations. The crux seems to be the nature of efficient computation. While there are some exceptions, typically when we ask whether a problem can be solved at all the answer is much simpler, and does not seem to require such a plethora of techniques as is the case when we ask whether the problem can be solved efficiently. Is this state of affairs inherent, or is it just a matter of time until algorithm design will become as boring as solving a single polynomial equation?
We will not answer this question in this course. However, it does motivate some of the questions we ask, and the investigations we pursue. In particular, this motivates the study of general algorithmic frameworks as opposed to tailor-made algorithms for particular problems. There is also a practical motivation for this as well: real world problems often have their own kinks and features, and will rarely match up exactly to one of the problems in the textbook. A general algorithmic framework can be applied to a wider range of problems, even if they have not been studied before.
There are several such general frameworks, but we will focus on one example that arises from convex programming: the Sum of Squares (SOS) Semidefinite Programming Hierarchy. It has the advantage that on the one hand it is general enough to capture many algorithmic
techniques, and on the other hand it is specific enough that (if we are careful) we can avoid the “curse of completeness”. That is, we can actually prove impossibility results or lower bounds for this framework without inadvertently resolving questions such as 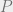
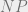
The Sum of Squares Algorithm
Let us now take a step back from the pompous rhetoric and slowly start getting around to the mathematical contents of this course. It will be mostly be focused on the Sum of Squares (SOS) semidefinite programming hierarchy. In a sign that perhaps we did not advance so much from the middle ages, the SOS algorithm is also a method for solving polynomial
equations, albeit systems of several equations in several variables. However, it turns out that this is a fairly general formalism. Not onlyis solving such equations, even in degree two, NP-hard, but in fact one can often reduce directly to this task from problems of interest in a fairly straightforward manner.For example, given a 3SAT formula of a form such as 
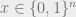

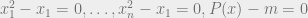

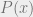
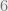
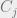





We will be interested in solving such equations over the real numbers, and typically in settings where (a) the polynomials in questions are low degree, and (b) obtaining an approximate solution is essentially as good as obtaining an exact solution, which helps avoid at least some issues of precision and numerical accuracy. Nevertheless, this is still a very challenging setting. In particular, whenever there is more than one equation, or the degree is higher than two, the task of solving polynomial equations becomes non convex, and generally speaking, there can be exponentially many local minima for the “energy function” which is obtained by summing up the square violations of the equations. This is problematic since many of the tools we use to solve such equations involve some form of local search, maintaining at each iteration a current solution and looking for directions of improvements. Such methods can and will get “stuck” at such local minima.
When faced with a non-convex problem, one approach that is used in both practice and theory is to enlarge the search space. Geometrically, we hope that by adding additional dimensions, one may find new ways to escape local minima. Algebraically, this often amounts to adding additional variables, with a standard example being the linearization technique where we reduce, say, quadratic equations in 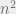

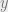
The SOS algorithm is a systematic way of enlarging the search space, by adding variables in just such a manner. In the example above it adds in the additional constraint that if the matrix 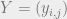







History
The SOS algorithm has its roots in questions raised in the late 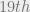

By the arithmetic-mean geometric-mean inequality, 
In his famous 1900 address, Hilbert asked as his 17th problem whether any polynomial can be represented as a sum of squares of rational functions. (For example, Motzkin’s polynomial above can be shown to be the sum of squares of four rational functions of denominator and numerator degree at most 
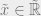


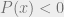
Later in the 60’s and 70’s, Krivine and Stengle extended this result to show that any unsatisfiable system of polynomial equations can be certified to be unsatisfiable via a Sum of Squares (SOS) proof (i.e., by showing that it implies an equation of the form
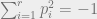

In the late 90’s / early 2000’s, there were two separate efforts on getting quantitative / algorithmic versions of this result. On one hand Grigoriev and Vorobjov (1999) asked the question of how large the degree of an SOS proof needs to be, and in particular Grigoriev (1999,2001) proved several lower bounds on this degree for some interesting polynomials. On the other hand Parrilo (2000) and Lasserre (2001) independently came up with hierarchies of algorithms for polynomial optimization based on the Positivstellensatz using semidefinite programming. (A less general version of this algorithm was also described by Naum Shor in a 1987 Russian paper, which was cited by Nesterov in 1999.)
It turns that the SOS algorithm generalizes and encapsulates many other convex-programming based algorithmic hierarchies such as those proposed by Lovász and Schrijver and Sherali and Adams, and other more specific algorithmic techniques such as linear programming and spectral techniques. As mentioned above, the SOS algorithm seems to achieve a “goldilocks” balance of being strong enough to capture interesting techniques but weak enough so we can actually prove lower bounds for it. One of the goals of this course (and line of research) is to also understand what algorithmic techniques can not be captured by SOS, particularly in the setting (e.g., noisy low-degree polynomial optimization) where it seems most appropriate for.
Applications of SOS
SOS has applications to: equilibrium analysis of dynamics and control (robotics, flight controls, …), robust and stochastic optimization, statistics and machine learning, continuous games, software verification, filter design, quantum computation and information, automated theorem proving, packing problems, etc…

SOS was used to analyze the “falling leaf” mode of the U.S. Navy
F/A-18 “Hornet”, see A. Chakraborty, P. Seiler, and G. J. Balas, Journal
of guidance, control, and dynamics, 34(1):73–85, 2011. (Image credit:
Wikipedia)

Bachoc and Vallentin used sum-of-squares to give the best known upper
bounds for sphere kissing numbers in higher dimensions. See “New upper
bounds for kissing numbers from semidefinite programming”, C Bachoc, F
Vallentin, Journal of the American Mathematical Society 21 (3), 909-924.
(Image credit: A. Traffas)
The TCS vs Mathematical Programming view of SOS
The SOS algorithm is intensively studied in several fields, but
different communities emphasize different aspect of it. The main
characteristics of the Theoretical Computer Science (TCS) viewpoint, as
opposed to that of other communities are:
- In the TCS world, we typically think of the number of variables
and
would take something like a petabyte of memory. This may justify the optimization/control view of keeping
- Typically in TCS our inputs are discrete and the polynomials are simple, with integer coefficients and constraints such as
that restrict attention to the Boolean cube. Thus we are less concerned with issues of numerical accuracy,
boundedness, etc.. - Traditionally people have been concerned with exact convergence of the SOS algorithm— when does it yield an exact solution to the optimization problem. This often precludes
of a solution to the equations, this raises the question of a obtaining rounding algorithms, which are procedures to translate the output of the algorithm to an approximate solution.
SOS as a “cockroach”
In theoretical computer science we typically define a computational problem 
This is a general phenomenon that occurs time and again many fields, known under many names including the “bias variance tradeoff”, the “stability plasticity dilemma”, “performance robustness tradeoff” and many others. That is, there is an inherent tension between optimally solving a particular question (or optimally adapting to a particular environment) and being robust to changes in the question/environment (e.g., avoiding “overfitting”). For example, consider the following two species that roamed the earth few hundred million years ago during the Mesozoic era. The dinosaurs were highly complex animals that were well adapted to their environment. In contrast cockroaches have extremely simple reflexes, operating only on very general heuristics such as “run if you feel a brush of air”. As one can tell by the scarcity of “dinosaur spray” in stores today, it was the latter species that was more robust to changes in the environment. With that being said, we do hope that the SOS algorithm is at least approximately optimal in several interesting settings.
