Here is a quick overview of my intuitions on where we are with AI safety in early 2026:
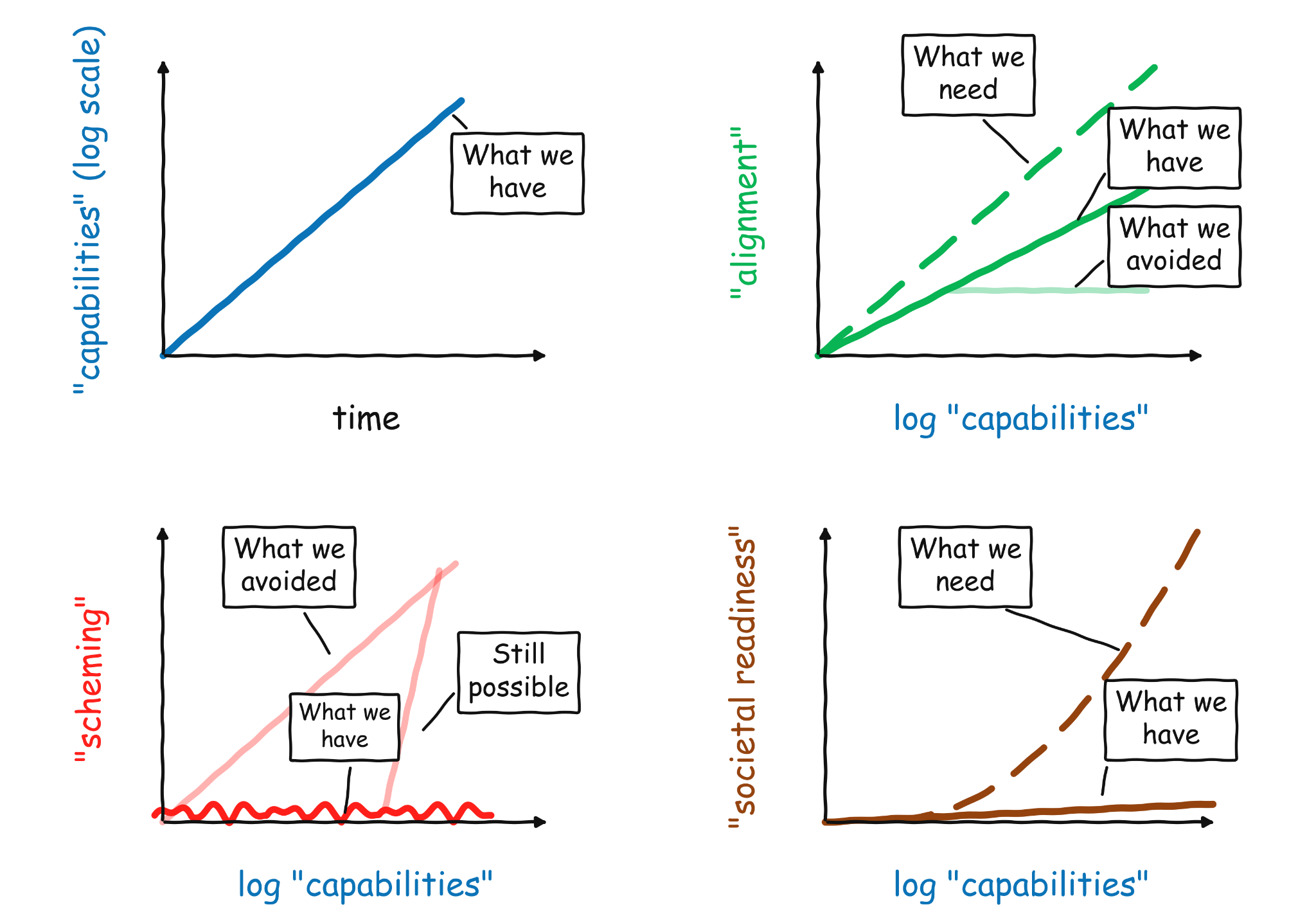
- So far, we continue to see exponential improvements in capabilities. This is most visible in the famous “METR graph”, but the trend is clear in many other metrics, including revenue. If you squint, you can even see a potential recent “bending upward” of the curve, as we are starting to use AI to accelerate the development of AI.
- We see some good news in alignment – as models become more capable, they are also more aligned, across multiple measures, including spec compliance. However, the improvement is not sufficient to match the higher stakes that come up with improved capabilities. We still have not fully solved challenges like adversarial robustness, dishonesty, and reward hacking, and we are still far from the standards of reliability and security that are required in high stake applications. (See slide below from Nicholas Carlini’s lecture in my AI safety course.) We also need to extend alignment beyond its traditional focus on the behavior of a model in an isolated conversation and in particular monitoring and aligning systems with a vast number of agents. Increasing the slope of the “alignment line” is the main focus of my technical research– working on building machines of faithful obedience that have good values but do not “legislate from the bench”.
One might argue that current alignment is “good enough” for an automated alignment researcher, and the AIs can take it from here. I disagree. I do not believe that all alignment is missing is one clever idea. Rather, we need ways to productively scale up compute into improving intent-following, honesty, monitoring, multi-agent alignment. This work will require multiple iterations of empirical experiments. AI can assist us in these, but it will not be a magic bullet. Also, we cannot afford to wait for AI to solve alignment for us, since in the meantime it will keep getting deployed in higher and higher stakes (including capability research).
- One piece of good news is that we have arguably gone past the level where we can achieve safety via reliable and scalable human supervision, but are still able to improve alignment. Hence we avoided what could have been a plateauing of alignment as RLHF runs out of steam. This is related to the fact that we do not see very significant scheming or collusion in models, and so we are able to use models to monitor other models! (e.g., see this). This is perhaps the most important piece of good news on AI safety we have seen so far. We need to keep tracking this! (In particular, if models become schemers, then since they are already quite situationally aware, it will be hard to even measure their alignment, let alone improve it.) But there is reason to hope this trend will persist.
- The worst news is that society is not ready for AI, and is not showing signs of getting ready. Whether it is facing increasing capabilities in areas like bio and cyber (including increasing capabilities of open source models), preparing for economic disruptions, enacting regulations and laws to protect democracy and individual empowerment (e.g., avoid scenarios like a country of IRS agents in a datacenter), or international collaborations on AI safety, our governments and institutions are not rising up to the challenge. This is perhaps the best argument for an “AI pause,” but (a) I do not think such a pause is feasible or practical, and (b) I am not confident that governments will use this time wisely— experience shows that it is hard to overestimate government’s capability for inaction.
`

