Hastad‘s Switching Lemma is one of the gems of computational complexity. The switching lemma analyzes the effect of random restrictions on  circuits, which are constant depth circuits with AND, OR and NOT gates of unbounded fanin. It says that such restrictions tends to simplify circuits in surprising ways. An immediate consequence of the switching lemma is strong lower bounds for circuits. It also has important applications in Fourier analysis, computational learning, pseudorandomness and more. Hastad’s lemma builds on earlier work due to Ajtai, Furst-Saxe-Sipser and Yao.
circuits, which are constant depth circuits with AND, OR and NOT gates of unbounded fanin. It says that such restrictions tends to simplify circuits in surprising ways. An immediate consequence of the switching lemma is strong lower bounds for circuits. It also has important applications in Fourier analysis, computational learning, pseudorandomness and more. Hastad’s lemma builds on earlier work due to Ajtai, Furst-Saxe-Sipser and Yao.
The crux of the matter is to analyze the effect of a random restriction on small-width DNF formulae. For this we need some notation. Let 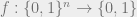 be a Boolean function on
be a Boolean function on  input variables.
input variables.
- A random restriction with parameter
 is one where we leave a variable alive with probability and set it randomly to
is one where we leave a variable alive with probability and set it randomly to  with probability
with probability  . We use
. We use  to denote the restricted function.
to denote the restricted function.
- We use
 to denote the depth of the shallowest decision tree that computes
to denote the depth of the shallowest decision tree that computes  and
and 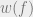 to denote the width of the smallest width DNF formula that computes it.
to denote the width of the smallest width DNF formula that computes it.
It is easy to see that 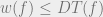 , or rather that having a small depth decision tree implies having a small-width DNF representation. There is no converse to this statement: it is not hard to construct examples of functions where is exponentially smaller than , indeed the Tribes functions is such an example.
, or rather that having a small depth decision tree implies having a small-width DNF representation. There is no converse to this statement: it is not hard to construct examples of functions where is exponentially smaller than , indeed the Tribes functions is such an example.
Hastad’s switching lemma tells us that although a small-width DNF might not have a small decision tree, a random restriction of almost certainly does. The precise statement is the following:
Hastad’s Switching Lemma: Let 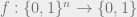 be a width
be a width  DNF. Let denote the function obtained by applying a random restriction with probability to it. Then
DNF. Let denote the function obtained by applying a random restriction with probability to it. Then
![Pr_\rho[DT(f_\rho) \geq k] \leq (5pw)^k](https://s0.wp.com/latex.php?latex=Pr_%5Crho%5BDT%28f_%5Crho%29+%5Cgeq+k%5D+%5Cleq+%285pw%29%5Ek&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Lets try and digest this statement. Think of as a parameter between  and
and  . Let us pick the restrcition paramter
. Let us pick the restrcition paramter  so that the RHS becomes
so that the RHS becomes 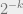 .
.
We are keeping variables alive with probability 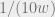 , which is not too high, but we can reasonably expect about
, which is not too high, but we can reasonably expect about  variables to remain alive. Nevertheless, the switching lemma tells us that the resulting function has decision tree depth
variables to remain alive. Nevertheless, the switching lemma tells us that the resulting function has decision tree depth  with probability
with probability  . Now a decision tree of depth is a
. Now a decision tree of depth is a  -junta. So only a miniscule number of live variables continue to matter.
-junta. So only a miniscule number of live variables continue to matter.
One could do this all day, nearly every setting of relevant parameters  gives something fairly surprising. But perhaps the most surprising of all is the irrelevant parameter: the number of terms
gives something fairly surprising. But perhaps the most surprising of all is the irrelevant parameter: the number of terms  (which is so irrelevant that we had not given it a symbol so far), or equivalently the number of variables. Surely and/or should matter in the statement somewhere? Any reasonable person trying to prove this statement would probably first try a union bound over all terms and run smack into . As a colleague once said, the realization that is irrelevant is mind-expanding.
(which is so irrelevant that we had not given it a symbol so far), or equivalently the number of variables. Surely and/or should matter in the statement somewhere? Any reasonable person trying to prove this statement would probably first try a union bound over all terms and run smack into . As a colleague once said, the realization that is irrelevant is mind-expanding.
By now there have been several alternate proofs of the switching lemma, I particularly like the exposition here due to Neil Thapen.
As scientists, when faced with magic, we try to find rationalizations for it. One possible rationalization for the absence of the number of variables/terms in the switching lemma could be that small-width DNFs are not too complex to start with. Sure they are not as simple as juntas, but they are not far being juntas either. A statement of this form in fact follows from Friedgut‘s junta theorem. Friedgut’s theorem tells us that any function with average sensitivity  is close to a
is close to a  -junta. We can apply Friedgut’s theorem in this context since it is not hard to show that a width- DNF formula has average sensitivity bounded by
-junta. We can apply Friedgut’s theorem in this context since it is not hard to show that a width- DNF formula has average sensitivity bounded by  . A similar but weaker statement can be derived from the work of Ajtai-Wigderson and Trevisan, who show how to approximate small width DNFs by decision trees.
. A similar but weaker statement can be derived from the work of Ajtai-Wigderson and Trevisan, who show how to approximate small width DNFs by decision trees.
Some recent work with Raghu Meka and Omer Reingold takes a step towards converting this inutition into a proof of the switching lemma. We show that any width DNF is  -close to a width DNF that has no more than
-close to a width DNF that has no more than  terms. Moreover, we prove a stronger approximation guarantee called sandwiching approximation which is often useful in pseudorandomness (see paper for details).
terms. Moreover, we prove a stronger approximation guarantee called sandwiching approximation which is often useful in pseudorandomness (see paper for details).
This statement is incomparable with the earlier consequence derived from Friedgut’s theorem, the dependence on is worse, but the dependence on is better, and the approximators are themselves width DNF formulas. Which strongly suggests a single best-of-both-worlds kind of statement, we pose this as a conjecture in our paper:
Conjecture: Any width DNF is  -close to a width DNF that has no more than
-close to a width DNF that has no more than  terms.
terms.
If true, this says that any width DNF is well-approximated by a ( width) DNF with only 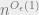 terms. If one can actually show sandwiching approximations, this would lead to a “union bound over terms” style proof of the switching lemma. The best lower bound we know comes from the Majority function on
terms. If one can actually show sandwiching approximations, this would lead to a “union bound over terms” style proof of the switching lemma. The best lower bound we know comes from the Majority function on  variables, which shows that one needs at least
variables, which shows that one needs at least 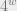 terms.
terms.
Parikshit
