
Scribe notes by Manos Theodosis
Previous post: A blitz through statistical learning theory Next post: Unsupervised learning and generative models. See also all seminar posts and course webpage.
Lecture video – Slides (pdf) – Slides (powerpoint with ink and animation)
In this lecture, we talk about what neural networks end up learning (in terms of their weights) and when, during training, they learn it.
In particular, we’re going to discuss
- Simplicity bias: how networks favor “simple” features first.
- Learning dynamics: what is learned early in training.
- Different layers: do the different layers learn the same features?
The type of results we will discuss are:
- Gradient-based deep learning algorithms have a bias toward learning simple classifiers. In particular this often holds when the optimization problem they are trying to solve is “underconstrained/overparameterized”, in the sense that there are exponentially many different models that fit the data.
- Simplicity also affects the timing of learning. Deep learning algorithms tend to learn simple (but still predictive!) features first.
- Such “simple predictive features” tend to be in lower (closer to input) levels of the network. Hence deep learning also tends to learn lower levels earlier.
- On the other side, the above means that distributions that do not have “simple predictive features” pose significant challenges for deep learning. Even if there is a small neural network that works very well for the distribution, gradient-based algorithms will not “get off the ground” in such cases. We will see a lower bound for learning parities that makes this intuition formal.
What do neural networks learn, and when do they learn it?
As a first example to showcase what is learned by neural networks, we’ll consider the following data distribution where we sample points 




If we train a neural network to fit this distribution, we can see below that the neurons that are closest to the input data end up learning features that are highly correlated with the input (mostly linear subspaces at 45-degree angle, which correspond to one of the stripes). In the subsequent layers, the features learned are more sophisticated and have increased complexity.
Neural networks have simpler but useful features in lower layers
Some people have spent a lot of time trying to understand what is learned by different layers. In a recent work, Olah et al. dig deep into a particular architecture for computer vision, trying to interpret the features learned by neurons at different layers.
They found that earlier layers learn features that resemble edge detectors.
However, as we go deeper, the neurons at those layers start learning more convoluted (for example, these features from layer 

SGD learns simple (but still predictive) features earlier.
There is evidence that SGD learns simpler classifiers first. The following figure tracks how much of a learned classifier’s performance can be accounted for by a linear classifier. We see that up to a certain point in training all of the performance of the neural network learned by SGD (measured as mutual information with the label or as accuracy) can be ascribed to the linear classifier. They diverge only very near the point where the linear classifier “saturates,” in the sense that the classifier reachers the best possible accuracy for linear models. (We use the quantity 
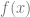
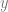
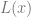
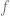
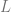

The benefits and pitfalls of simplicity bias
In general, simplicity bias is a very good thing. For example, the most “complex” function is a random function. However, if given some observed data ![{ (x_i,y_i)}_{i\in [n]}](https://s0.wp.com/latex.php?latex=%7B+%28x_i%2Cy_i%29%7D_%7Bi%5Cin+%5Bn%5D%7D&bg=ffffff&fg=666666&s=0&c=20201002)

At the same time, simplicity bias means that our algorithms might focus too much on simple solutions and miss more complex ones. Sometimes the complex solutions actually do perform better. In the following cartoon a person could go to the low-hanging fruit tree on the right-hand side and miss the bigger rewards on the left-hand side.

This can actually happen in neural networks. We also saw a simple example in class:

The two datasets are equally easy to represent, but on the righthand side, there is a very strong “simple classifier” (the 45-degree halfspace) that SGD will “latch onto.” Once it gets stuck with that classifier, it is hard for SGD to get “unstuck.” As a result, SGD has a much harder time learning the righthand dataset than the lefthand dataset.
Analysing SGD for over-parameterized linear regression
So, what can we prove about the dynamics of gradient descent? Often we can gain insights by studying linear regression.

Formally, given 
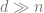

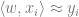
In this setting, we can prove that running SGD (from zero or tiny initialization) on the loss 


However note that 

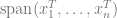


Geometrically this translates into
Analyzing the dynamics of descent, we can write the distance between consecutive weight updates and the converging solution as
We see that we are applying the linear operator 

This directly translates into 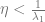
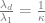

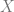
What happens now if the matrix
- if
, then the matrix
has
and the eigenvalues are bounded away from
. This means that the matrix is well conditioned.
- if
, then the spectrum of
- if
, then the spectrum has some zero eigenvalues, but is otherwise bounded away from zero. If we restrict to the subspace of positive eigenvalues, we achieve again a good condition number.

Deep linear networks
We now want to go beyond linear regression and talk about deep networks. As deep networks are very hard to understand, we will first start analyzing a depth 

Specifically, we can see that the minimum loss attained by the two models will coincide, i.e., 
We will analyze the gradient flow on these two networks (which is gradient descent with the learning rate 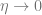

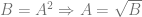


Gradient flow on the linear model simply gives 
since 

For simplicity, let’s denote 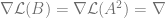


Another way to view the comparison between the models of interest, 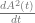



We can view this as follows: when we multiply the gradient with 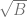
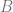
To see why, you can think of a low rank matrix has one that has few large eigenvalues and the others small. If 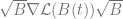

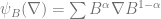
This means that we end up doing gradient flow on a Riemannian manifold. An interesting result is that the flow induced by the operator 
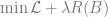

What is learned at different layers?
Finally, let’s discuss what is learned by the different layers in a neural network. Some intuition people have is that learning proceeds roughly like the following cartoon:

We can think of our data as being “built up” as a sequence of choices from higher level to lower level features. For example, the data is generated by first deciding that it would be a photo of a dog, then that it would be on the beach, and finally low-level details such as the type of fur and light. This is also how a human would describe this photo. In contrast, a neural network builds up the features in the opposite direction. It starts from the simplest (lowest-level) features in the image (edges, textures, etc.) and gradually builds up complexity until it finally classifies the image.
How neural networks learn features?
To build a bit of intuition, consider an example of combining different simple features. We can see that if we try to combine two good edge detectors with different orientations, the end result will hardly be an edge detector.
So the intuition is that there is competitive/evolutionary pressure on neurons to “specialize” and recognize useful features. Initially, all the neurons are random features, which can be thought of as random linear combination of the various detectors. However, after training, the symmetry will break between the neurons, and they will specialize (in this simple example, they will either become vertical or horizontal edge detectors).
Raghu, Gilmer, Yosinski, and Sohl-Dickstein tracked the speed at which features learned by different layers reach their final learned state. In the figure below the diagonal elements denote the similarity of the current state of a layer to its final one, where lighter color means that the state is more similar. We can see that earlier layer (more to the left) reach their final state earlier (with th exception of the 2 layers closest to the output that also converge very early).

The “symmetry breaking” intuition is explored by a recent work of Frankle, Dziugaite, Roy, and Carbin. Intuitively, because the average of two good features is generally not a good feature, averaging the weights of two neural networks with small loss will likely result in a network with large loss. That is, if we start from two random initializations 

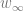


In contrast, Frankle et al showed that sometimes, when we start from the same initialization (especially after pruning) and use random SGD noise (obtained by randomly shuffling the training set) then we reach a “linear plateu” of the loss function in which averaging two networks yields a network with similar loss:

The contrapositive of simplicity: lower bounds for learning parities
If we believe that networks learn simple features first, and learn them in the early layers, then this has an interesting consequence. If the data has the form that simple features (e.g. linear or low degree) are completely uninformative (have no correlation with the label) then we may expect that learning cannot “get off the ground”. That is, even if there exists a small neural network that can learn the class, gradient based algorithms such as SGD will never find it. (In fact, it is possible that no efficient algorithm could find it.) There are some settings where we can prove such conjectures. (For gradient-based algorithms that is; proving this for all efficient algorithms would require settling the P vs NP question.)
We discuss one of the canonical “hard” examples for neural networks: parities. Formally, for ![I\subset [d]](https://s0.wp.com/latex.php?latex=I%5Csubset+%5Bd%5D&bg=ffffff&fg=666666&s=0&c=20201002)
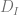





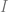


It turns out that if we don’t restrict ourselves to deep learning, given 


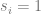


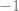
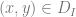
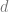

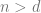
Switching to the learning setting, we can express parities by using few ReLUs. In particular, we’ve shown that we can create a step function using 



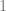


![I=[d]](https://s0.wp.com/latex.php?latex=I%3D%5Bd%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![\sum_{k \text{ odd } \in [d]} f_k(\sum_{i=1}^d (1-x_i)/2 )](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk+%5Ctext%7B+odd+%7D+%5Cin+%5Bd%5D%7D+f_k%28%5Csum_%7Bi%3D1%7D%5Ed+%281-x_i%29%2F2+%29&bg=ffffff&fg=666666&s=0&c=20201002)
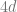

Parities are an example of a case where simple feature are uninformative. For example, if 

![\mathbb{E}_{(x,y) \sim D_I}[ L(x)y] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%28x%2Cy%29+%5Csim+D_I%7D%5B+L%28x%29y%5D+%3D+0&bg=ffffff&fg=666666&s=0&c=20201002)
in other words, there is no correlation between the linear function and the label.
To see why this is true, write 
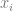


![\mathbb{E}[x_i y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bx_i+y%5D&bg=ffffff&fg=666666&s=0&c=20201002)






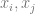


This lack of correlation turns out to be a real obstacle for gradient-based algorithms. While small neural networks for parities exist, and Gaussian elimination can find them, it turns out that gradient-based algorithms such as SGD will fail to do so. Parities are hard to learn, and even if the capacity of the network is such that it can memorize the input, it will still perform poorly in a test set. Indeed, we can prove that for every neural network architecture 
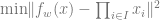
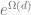
We now sketch the proof that gradient-based algorithms require exponentially many steps to learn parities, following Theorem 1 of Shalev-Shwartz,Shamir and Shammah. We think of an idealized setting where we have an unlimited number of samples and only use a sample 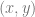


![\nabla_w \parallel f_w(x) - \chi_I(x) \parallel^2 = 2\sum_{i=1}^d \left [ f_w(x) \tfrac{d}{d x_i}f_{w}(x)- \chi_I(x)\tfrac{d}{d x_i}f_{w}(x) \right]](https://s0.wp.com/latex.php?latex=%5Cnabla_w+%5Cparallel+f_w%28x%29+-+%5Cchi_I%28x%29+%5Cparallel%5E2+%3D+2%5Csum_%7Bi%3D1%7D%5Ed+%5Cleft+%5B+f_w%28x%29+%5Ctfrac%7Bd%7D%7Bd+x_i%7Df_%7Bw%7D%28x%29-+%5Cchi_I%28x%29%5Ctfrac%7Bd%7D%7Bd+x_i%7Df_%7Bw%7D%28x%29+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
The term 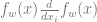
![\left(\mathbb{E}_x[ \chi_I(x)\tfrac{d}{d x_i}f{w}(x) ] \right)^2](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Cmathbb%7BE%7D_x%5B+%5Cchi_I%28x%29%5Ctfrac%7Bd%7D%7Bd+x_i%7Df%7Bw%7D%28x%29+%5D+%5Cright%29%5E2&bg=ffffff&fg=666666&s=0&c=20201002)

Formally, we will prove the following lemma:
Lemma: For every
![\mathbb{E}_I \left(\mathbb{E}_x[ \chi_I(x)\tfrac{d}{d x_i}f{w}(x) ] \right)^2 \leq \tfrac{poly(d,n)\mathbb{E}_x \frac{d}{d x_i}f{w}(x)^2}{2^d}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_I+%5Cleft%28%5Cmathbb%7BE%7D_x%5B+%5Cchi_I%28x%29%5Ctfrac%7Bd%7D%7Bd+x_i%7Df%7Bw%7D%28x%29+%5D+%5Cright%29%5E2+%5Cleq+%5Ctfrac%7Bpoly%28d%2Cn%29%5Cmathbb%7BE%7D_x+%5Cfrac%7Bd%7D%7Bd+x_i%7Df%7Bw%7D%28x%29%5E2%7D%7B2%5Ed%7D&bg=ffffff&fg=666666&s=0&c=20201002)
Proof: Let us fix 
![\mathbb{E}_x[ \chi_I(x)\tfrac{d}{d x_i}f{w}(x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_x%5B+%5Cchi_I%28x%29%5Ctfrac%7Bd%7D%7Bd+x_i%7Df%7Bw%7D%28x%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
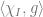

![{ \chi_I }{I\subseteq [d]}](https://s0.wp.com/latex.php?latex=%7B+%5Cchi_I+%7D%7BI%5Csubseteq+%5Bd%5D%7D&bg=ffffff&fg=666666&s=0&c=20201002)
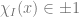
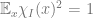


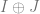
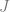



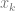
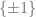
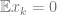

Given the above
![\mathbb{E}_x g(x)^2 = \langle g,g\rangle = \sum_{I \subseteq [d]} \langle g , \chi_I \rangle^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_x+g%28x%29%5E2+%3D+%5Clangle+g%2Cg%5Crangle+%3D+%5Csum_%7BI+%5Csubseteq+%5Bd%5D%7D+%5Clangle+g+%2C+%5Cchi_I+%5Crangle%5E2&bg=ffffff&fg=666666&s=0&c=20201002)
which means that (since there are 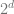
![[d]](https://s0.wp.com/latex.php?latex=%5Bd%5D&bg=ffffff&fg=666666&s=0&c=20201002)



2 thoughts on “What do deep networks learn and when do they learn it”