
This Spring and Summer I am doing some major editing to my text on introduction to theoretical computer science. I am adding figures (176 so far and counting..), examples, exercises, simplifying explanations, reducing footnotes, and mainly trying to make it more “user friendly” and less “idiosyncratic”. I am now adding in all chapters figures such as the following that outline the main results and how they are connected to one another.



Specifically, in the previous version of the book I used programming languages as the main computational models. While I still think this is the right way if we were to “start from scratch”, these idiosyncratic models made it harder for students to use other resources such as textbooks and lecture notes. They also make it more difficult for instructors to use individual chapters in their courses without committing to using the full book.
Hence in the new revision the standard models of Turing Machines and Boolean Circuits are front and center. We do talk about the programming-language equivalents as well, since I think they are important for the connection to practice and some concepts such as the duality of code and data are better explained in these terms. I also use the programming-language variants to demonstrate concepts to students in code including compilers from circuits to straightline programs, various “syntactic sugar” transformations, and the Cook-Levin Theorem and NP reductions.

One thing did not change – we still start with Boolean Circuits rather than automata as the initial computational model. Boolean circuits are closer to actual implementations of computing, are a finite (and hence simpler) model, but one that is non-trivial enough to allow showing some important theorems early in the course including existence of a circuit for computing every finite function, the existence of a circuit to evaluate other circuits, and the counting lower bound as well as the counting lower bound.
Circuits are also crucial for later material in the course since they make the proof of the Cook-Levin Theorem much simpler and cleaner, allow talking about results such as 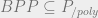

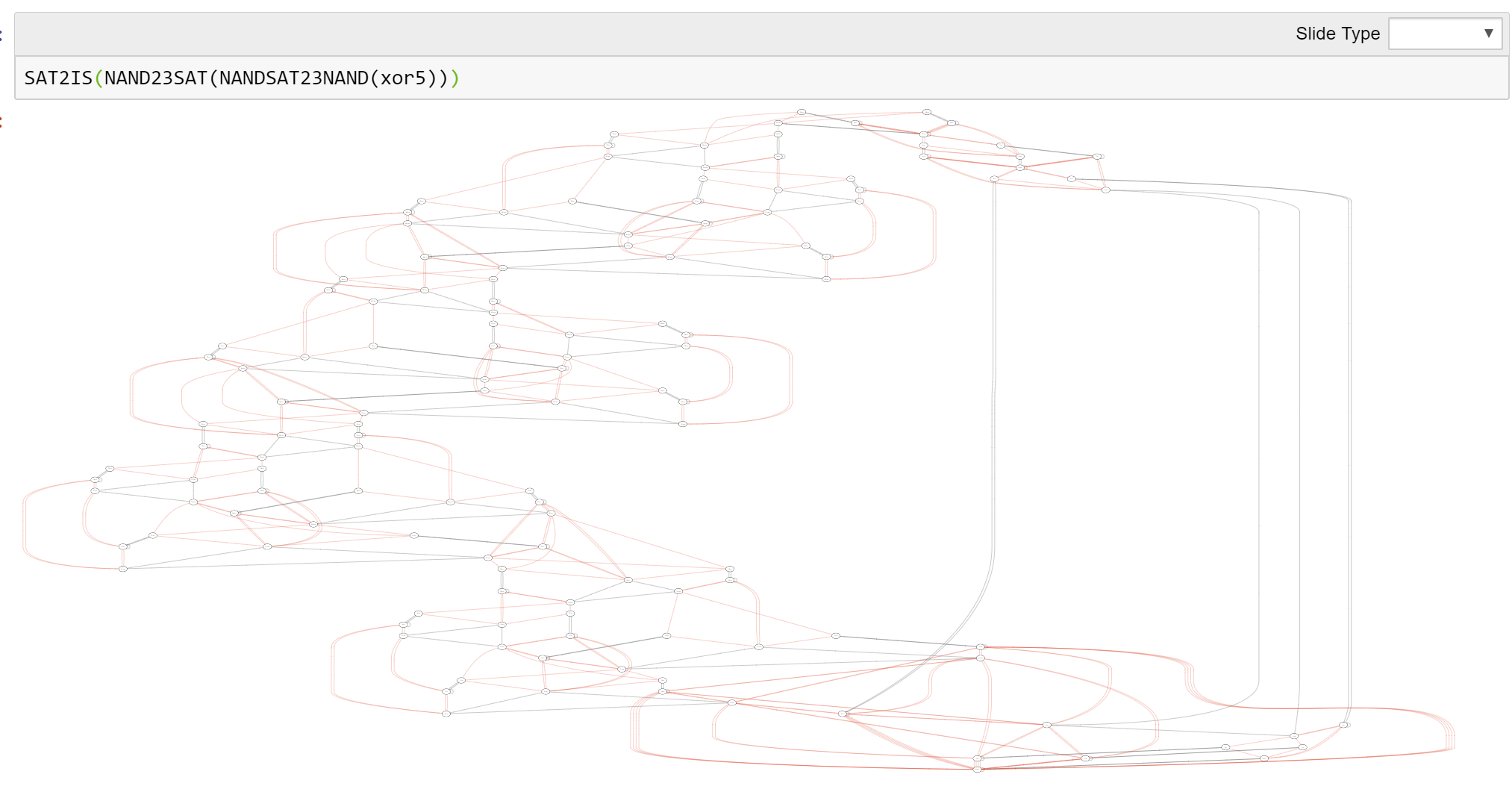
We do cover automata as well, including the equivalence of regular expressions and deterministic finite automata. We also cover context-free grammars (though not pushdown automata) and the λ calculus, including its equivalence with Turing Machines and the Y combinator (see also this notebook)
I have also done some work on the technical side of producing the book. The book is written in markdown. Markdown has many advantages but it wasn’t designed for 600-page technical books full of equations and cross-references so I did need to use some extensions to it. I am using pandoc (and my own filter) to produce both the HTML and LaTeX/PDF versions of the book.
There is still more work to do. I plan to add a chapter on space complexity and on proofs and computation (including both interactive and zero knowledge proofs, as well as the “propositions as types” correspondence between proofs and programs). I need to add more examples and exercises. There are also still several chapters where the text is “rough around the edges”.
As usual, the latest version of the book is available on https://introtcs.org . If you see any typo, problem, etc.., please post an issue on the GitHub repository (you can also make a pull request for small typo fixes if you prefer)
