As I mentioned before, I am teaching CS 121 at Harvard, and have written my own text, with the (not very original) title “Introduction to Theoretical Computer Science” . I am hoping for this text to turn into a published textbook in the next year or two. Toward this end, I would be grateful for any comments or suggestions on the text, as I will be working on it over the summer.
You can use the issues page on the GitHub repository to make any suggestions, corrections, reports on bugs and typos, and so on.
I also hope that others instructors would consider using this text in their courses, and would welcome suggestions as to what I can do to help in that. In particular, over the summer I plan to add more exercises (including some solved ones) and more examples, as well as more explanations and “proof ideas” for many of the theorems.
The main differences between this text and “classical approaches” to intro theory courses such as Sipser’s are the following:
Circuits / straightline programs as the basic model instead of automata
I do not start with finite automata as the basic computational model, but rather with straight-line programs (or, equivalently Boolean circuits) in an extremely simple programming language which I call the “NAND programming language” since its only operation is assigning to one variable the NAND of two others.
Automata are discussed later in the course, after Turing machines and undecidability, as an example for a restricted computational model where problems such as halting are effectively solvable. This actually corresponds to the historical ordering: Boolean algebra goes back to Boole’s work in the 1850’s, Turing machines and undecidability were of course discovered in the 1930’s, while finite automata were introduced in the 1943 work of McCulloch and Pitts but only really understood in the seminal 1959 work of Rabin and Scott. More importantly, the main current practical motivations for restricted models such as regular and context free languages (whether it is for parsing, for analyzing liveness and safety, or even for routing on software defined networks) are precisely because these are tractable models in which semantic questions can be effectively answered. This motivation can be better appreciated after students see the undecidability of semantic properties of general computing models.
Moreover, the Boolean circuit / straightline programs model is extremely simple to both describe and analyze, and some of the main lessons of the theory of computation, including the notions of the duality between code and data, and the idea of universality, can already be seen in this context. Nonuniform computation also gives essential background for some exciting topics I like to cover later in the course. For example, cryptography (making sense of notions such as “256 bits of security” or difficulty of bitcoin mining), pseudorandom generators and the conjecture that BPP=P, and quantum computing. Circuits of course also yield the simplest proof of the Cook Levin theorem.
A programming language instead of Turing machines for modeling uniform computation
Instead of Turing Machines, I introduce uniform computation using an equivalent model obtained by extending the straightline NAND programming language mentioned above to include loops and arrays (I call the resulting programming language “NAND++”). I do define Turing machines and show the equivalence to NAND++ program, so the students can connect this both to the historical context as well to other literature they may encounter.
I believe that the programming language formalism makes this model more concrete and familiar to the students than Turing machines. For examples, a result such as the equivalence of Turing machines with two dimensional tapes and one dimensional tapes is now described as showing that a language with two dimensional arrays can be “transpiled” into a language with one dimensional arrays only (i.e., two dimensional arrays can be implemented via “syntactic sugar”).
Moreover, because the NAND++ programming language is extremely simple and fully specified, it is easy to show its formal equivalence with TM’s. In fact, since NAND++ is essentially obtained by adding a “feedback loop” to Boolean circuits, this makes the Cook Levin theorem easier to prove. I even implemented the Cook Levin reduction in a Python notebook, and so students can see how one can transform a NAND++ program 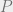
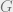




I also introduce yet another extension of NAND++ that allows indirect access to arrays, and hence is essentially equivalent to the standard RAM machine model used (implicitly) in algorithms courses. (I call this language NAND<<.) Using a RAM based model makes the distinction between notions such as 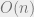
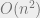
More advanced topics
Reducing the time dedicated to automata (and eliminating context free languages, though I do touch on them in the text in an optional section) allows to spend more time on topics such randomness and computation, the interactions between proofs and programs (including Gödel’s incompleteness, interactive proof systems, and even a bit on the 
The book is still work in progress, but I think is already quite usable as a textbook. Indeed, much of the feedback I got on the course was that people were happy with the text (though perhaps they merely preferred it to the lectures due to my teaching abilities 🙂 ). One student even got me this coffee mug:

In any case, I hope to get more comments as I work on it over the summer. Regardless of whether or not it’s eventually published as a book, I intend to keep a version of it freely available online.

similar to Savage Models of Computation. 1998. personally like TMs more for undergraduate and circuits for graduate work. circuits for more advanced undergrad students. maybe its best to emphasize turing competeness and then talk about how many models are equivalent.
Click to access ModelsOfComputation.pdf
Is the slight reduction in gates worth the loss of heuristic understanding when using NAND instead of AND, OR, NOT? The equivalence is shown anyway, and NAND can be used as a shortcut only when this really simplifies proofs.
One of the points we want to make fairly quickly is that NAND doesn’t make much difference.
Indeed, I initially present the model with AND, OR, NOT, and then say we can implement them with NAND (and vice versa). Then very quickly we talk about how if once we showed once that we can implement a function (such as IF, XOR, MAJORITY or whatever) then we can use it in all future discussions.
NAND does make life easier in some proofs, when we don’t have to do any case analysis on three different types of gates, and any restricted gateset, including AND,OR,NOT will be very limited.