Now that the important event of the STOC deadline has passed, we can talk about trivial matters such as the future of the free world (but of course, like a broken record, I will come back to talking about sum of squares by the end of the post).
A priori predicting the result of the election seems like an unglamorous and straighforward exercise: you ask 



Yet somehow, different analysts looking at the polls come up with very different numbers for the probability that Trump will win. As of today 538 says it is 34.2%, NY-times’ Upshot says it is 14%, David Rotchschild’s predictwise says it is 16%, and Sam Wang’s PEC says it is 2%.
There are several reasons for this discrepancy, including the fact that the U.S. election is not won based on popular vote (though they almost always agree), that we need to estimate the fraction among actual voters as opposed to the general population, that polls could have systematic errors, and of course there is genuine uncertainty in the sense that some people might change their minds.
But at least one of the reasons seems to come up from a problem that TCS folks are familiar with, and arises in the context of rounding algorithms for convex optimization, which is to understand higher level correlations. For example, essentially all these predictors think that there are a few states such Florida, New Hampshire, Nevada, and North Carolina that have reasonable chance of going either way, but that Trump cannot afford to lose even one of them. Clearly these are not perfectly independent nor perfectly correlated events, but understanding the correlations between them seems hard, and appears to account for much of the huge discrepancy between the topline predictions.
Even if you do understand the correlations, using them to come up with predictions can be a computationally hard task. The typical way these people do it is to come up with an efficiently samplable distribution that matches the given marginals and correlations, and then run many simulations on this distribution to predict the outcome.
But coming up with efficiently sampleable distributions that match even simple pairwise or three-wise correlations is a computationally hard task. (For constrained pairwise moments this is related to MAX-CUT while for unconstrained higher moments this is related to SAT, it is possible to do this for unconstrained pairwise moments using the quadratic sampling lemma, also known as Gaussian copula, which is related to the hyperplane rounding technique of Geomans and Williamson.) For an empirical demonstration, see this blog post of David Rothschild for how it is problematic to find a distribution that matches both the statewise and topline marginals of prediction markets (despite a fact that such a distribution should exist under the efficient market hypothesis). The fact that the matching moments problem is hard in general means that people use different heuristics to achieve this, and I don’t know if they have a good understanding of how the choice of heuristic affects the quality of prediction.
In our sum of squares lecture notes we discuss (with a javascript-powered figure!) this issue with respect to the clique problem. Given a graph 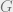




![\Pr[ |S| \neq k ] < 1](https://s0.wp.com/latex.php?latex=%5CPr%5B+%7CS%7C+%5Cneq+k+%5D+%3C+1&bg=eeeeee&fg=666666&s=0&c=20201002)
![\Pr [ \{ i,j \} \subseteq S ] >0](https://s0.wp.com/latex.php?latex=%5CPr+%5B+%5C%7B+i%2Cj+%5C%7D+%5Csubseteq+S+%5D+%3E0&bg=eeeeee&fg=666666&s=0&c=20201002)

