In this post I’d like to report a new and simple proof we found for theorem by Berenbrink, Czumaj, Steger, Vöcking on the imbalance of the balls-into-bins process known as the multiple choice scheme. Full details could be found in the paper. Probably many are familiar with this process, Kunal blogged about some variations of it a few months ago, in any case, I’ll start with a quick primer (shamelessly taken from Kunal’s blog post):
Balls-and-Bins processes are a name for randomized allocations processes, typically used to model the performance of hashing or more general load balancing schemes. Suppose there are  balls (think items) to be thrown into
balls (think items) to be thrown into  bins (think hash buckets). We want a simple process that will keep the loads balanced, while allowing quick decentralized lookup. We measure the balance in terms of the additive gap: the difference between the maximum load and the average load.
bins (think hash buckets). We want a simple process that will keep the loads balanced, while allowing quick decentralized lookup. We measure the balance in terms of the additive gap: the difference between the maximum load and the average load.
The simplest randomized process one can think of is what is called the one choice process: place each ball in an independently and uniformly sampled bin. Many of us studied the  case of this process in a randomized algorithms class, and we know that the load is
case of this process in a randomized algorithms class, and we know that the load is 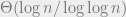 except with negligible probability (for the rest of the post, I will skip this “except with negligible probability” qualifier). What happens when is much larger than ? It can be shown that for large enough , the load is roughly
except with negligible probability (for the rest of the post, I will skip this “except with negligible probability” qualifier). What happens when is much larger than ? It can be shown that for large enough , the load is roughly  (see this paper for more precise behavior of the gap).
(see this paper for more precise behavior of the gap).
Can we do better? Azar, Broder, Karlin and Upfal analyzed the following two choice process: balls come sequentially, and each ball picks two bins independently and uniformly at random (say, with replacement), and goes into the less loaded of the two bins (with ties broken arbitrarily). They showed that when the load of the two choice process when is significantly better: only 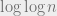 .
.
The proof uses a simple but clever induction. The induction is not on the number of balls nor on the number of bins. Say we know an upper bound  on the fraction of bins with load at least
on the fraction of bins with load at least  , the proof shows how do derive a bound
, the proof shows how do derive a bound 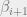 on the fraction of bins with load at least
on the fraction of bins with load at least  .
.
Induction base: Since only balls are thrown we know that at most 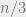 bins contain at least
bins contain at least 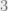 balls, so
balls, so 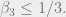
Induction step: As more balls are put in the bins the fraction of bins with load at least only increases, so if is an upper bound on the fraction of bins with load at least at the end of the process, it is also an upper bound in any other point in time. The key observation is that the number of bins of load at least is bounded by the number of balls which were placed at ‘height’ at least . For a ball to land at height at least both its choices need to be at height at least . The inductive hypothesis asserts that the fraction of such bins is at most , so the probability a ball indeed lands at height at least is at most  . There are such balls so the (expected) total number of balls (and thus bins) of height at least is at most
. There are such balls so the (expected) total number of balls (and thus bins) of height at least is at most  . In other words, the inductive step implies the following recurrence:
. In other words, the inductive step implies the following recurrence: 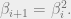
Since each inductive step the beta’s are squared, after steps the fraction is less than 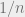 and (modulo some details) we are done!
and (modulo some details) we are done!
The proof as sketched above relies on the assumption that the number of balls is . We needed that for the base of the induction and for the inductive step. What happens when 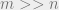 ? The technique as described above seems unfit to handle the heavily loaded case. Other proof techniques that use differential equations and witness trees also seem unsuited to analyze the heavily loaded case (See this nice survey).
? The technique as described above seems unfit to handle the heavily loaded case. Other proof techniques that use differential equations and witness trees also seem unsuited to analyze the heavily loaded case (See this nice survey).
A breakthrough was achieved in a remarkable paper by Berenbrink et al. In that paper they proved that the same bound on the gap holds for any, arbitrarily large number of balls:
Theorem: For every , the maximum load is  w.h.p.
w.h.p.
Note that the additive gap between maximum and average is independent of . Contrast this with the one choice case in which the additive gap diverges with the number of balls. This is very meaningful, say there are 100 bins and 100,000 balls, the gap between max and average is less than 3 with two choices, while it is roughly 80 when using one choice.
From a (very) high level their approach is the following: first they show that all the action is in the first poly balls, in other words, the gap after balls are thrown is distributed similarly to the gap after only poly balls are thrown. This is done by bounding the mixing time of the underlying Markov chain. The second step is to extend the induction sketched above to the case of poly balls. This turns out to be a major technical challenge which involves four inductive invariants and plenty of calculations, some of which are computer aided. Moreover, these calculations need to be redone whenever the model is tweaked.
balls, in other words, the gap after balls are thrown is distributed similarly to the gap after only poly balls are thrown. This is done by bounding the mixing time of the underlying Markov chain. The second step is to extend the induction sketched above to the case of poly balls. This turns out to be a major technical challenge which involves four inductive invariants and plenty of calculations, some of which are computer aided. Moreover, these calculations need to be redone whenever the model is tweaked.
Our hope is that our simpler proof will make this beautiful theorem more accessible.
We take a different approach. The main tool we use is a theorem from our previous paper on the topic which directly implies a weaker bound. This bound is then sharpened to yield the tight  bound on the gap. First we need a simple definition: The gap vector at time , denoted by
bound on the gap. First we need a simple definition: The gap vector at time , denoted by 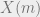 , is the dimensional vector specifying the additive gap(= load – average) of the bins after balls were thrown. The lemma we use states that an exponential potential function has linear expectation:
, is the dimensional vector specifying the additive gap(= load – average) of the bins after balls were thrown. The lemma we use states that an exponential potential function has linear expectation:
Lemma (1): There exist universal  such that
such that ![E[ \sum e^{a|X_i(m)|}] \leq bn](https://s0.wp.com/latex.php?latex=E%5B+%5Csum+e%5E%7Ba%7CX_i%28m%29%7C%7D%5D+%5Cleq+bn&bg=eeeeee&fg=666666&s=0&c=20201002)
What can we learn from the Lemma? It immediately implies a bound of  on the gap for every given . In fact the bound is on the gap between the maximum and minimum, and as such it is tight. What we need however is a finer bound of on the gap between maximum and average.
on the gap for every given . In fact the bound is on the gap between the maximum and minimum, and as such it is tight. What we need however is a finer bound of on the gap between maximum and average.
So, lets assume balls were thrown, and the max gap is say smaller than  . The key idea is to analyze what will happen after we throw
. The key idea is to analyze what will happen after we throw 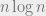 additional balls, i.e. at time
additional balls, i.e. at time 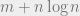 . First of all, the average would move up from
. First of all, the average would move up from  to
to  which is beyond the current max gap, so all balls contributing to the gap at time were indeed thrown in the last time steps. This means that we can now prove a bound for time by essentially repeating the inductive step as was described above. In the description above we used the fact that balls were thrown, but nothing terrible happens if balls are thrown instead. The more serious obstacle is to find a base case for time . Recall that when it must be the case that
which is beyond the current max gap, so all balls contributing to the gap at time were indeed thrown in the last time steps. This means that we can now prove a bound for time by essentially repeating the inductive step as was described above. In the description above we used the fact that balls were thrown, but nothing terrible happens if balls are thrown instead. The more serious obstacle is to find a base case for time . Recall that when it must be the case that 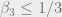 , this of course doesn’t hold when the number of balls is arbitrarily large.
, this of course doesn’t hold when the number of balls is arbitrarily large.
The crucial observation is that Lemma (1) gives just that! It shows that the fraction of bins of gap at least (at time ) is at most 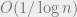 so we can start the argument with the base case
so we can start the argument with the base case  and then continue as usual.
and then continue as usual.
The induction essentially tells us that if we know that at time the gap was at most , then after throwing additional balls the gap is reduced to  . If we now throw
. If we now throw 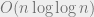 additional balls and repeat the argument, the gap is reduced to
additional balls and repeat the argument, the gap is reduced to 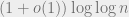 .
.
It is important to point out that we haven’t recovered the theorem of Berenbrink et.al. at full strength. We get a weaker tail bound for the probability the gap is larger than the expectation, as well as worse low order terms on the expectation itself.
On the plus side this technique is general enough to capture many variotions on the basic model. Consider for instance a scenario where balls are asigned random weights: when a ball is placed its weight is uniformly sampled from the set 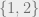 . One would naturally expect the maximum gap to be bounded by
. One would naturally expect the maximum gap to be bounded by 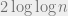 . Indeed the proof above shows just that with minimal changes.
. Indeed the proof above shows just that with minimal changes.

Would it be possible to please give a coefficient (or upper bound on a coefficient) for the $Theta(1)$ result in the heavily loaded case.
I don’t think the constant was hashed out explicitly in the paper of Berenbrink et. al. (in our paper we are loose with the low order terms). In any case, it is quite small and I believe that simulations would show that it is less than 3. But I’d be happy to stand corrected if someone has a better answer.
Thanks very much. Do you think there is a way to show that the constant is small analytically?