This post will be about differential privacy (DP), with a focus on what is often referred to in the differential privacy literature (often colloquially) as “privacy loss”. A brief recap of the setting: a trusted data curator has a database of sensitive information about individuals. The curator wants to release aggregate statistical information about the data, without compromising any individual’s privacy. Differential privacy (DP), due to Cynthia Dwork, Frank Mcsherry, Kobbi Nissim and Adam Smith, is a rigorous framework and security definition for algorithms that operate on sensitive data and publish aggregate statistics. Differential privacy aims to prevent any individual’s privacy from being compromised. Two unique advantages of differential privacy are: (1) it resists linkage attacks and auxiliary information, (2) it supplies a quantifiable measure of harm incurred by individuals and composes nicely.
In this blog post I’d like to discuss the second property. I’ll focus on a quantitive measure of “harm” incurred by an individual. In a future post I’ll build on this and elaborate on the “nice” composition properties of Differential Privacy, based on work with Cynthia Dwork and Salil Vadhan, and also on more recent work with Cynthia Dwork (but, since I couldn’t resist, I’ll give a couple of teasers about composition in this post).
Differential Privacy: Definition. An algorithm  (often referred to as a mechanism in the DP literature) satisfies
(often referred to as a mechanism in the DP literature) satisfies  -DP if for any database
-DP if for any database 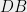 , an individual’s record
, an individual’s record  , and event
, and event 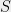 (over ‘s output space), the probabilities (over the ‘s coins), that event occurs when is run on: (1) the database
(over ‘s output space), the probabilities (over the ‘s coins), that event occurs when is run on: (1) the database  , comprising all records in together with record , (2) the database (without record ), are roughly similar: they are within a small multiplicative factor (close to 1) of each other.
, comprising all records in together with record , (2) the database (without record ), are roughly similar: they are within a small multiplicative factor (close to 1) of each other.
More formally, is -DP iff for all 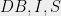 :
:
![\displaystyle \left| \ln \frac{\Pr_A [A(DB+I) \in S]}{\Pr_A [A(DB)\in S]} \right| \leq \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%7C+%5Cln+%5Cfrac%7B%5CPr_A+%5BA%28DB%2BI%29+%5Cin+S%5D%7D%7B%5CPr_A+%5BA%28DB%29%5Cin+S%5D%7D+%5Cright%7C+%5Cleq+%5Cepsilon&bg=eeeeee&fg=000000&s=0&c=20201002)
Typically, we think of as a small positive constant. Intuitively, DP means that any event that can occur when my data are considered, would have occurred with roughly the same probability even if my data were never considered. One interpretation of this guarantee, is that individuals’ participation in the analysis will not lead to significant harm.
Privacy Loss for Outcome  . For database , individual , and outcome , the privacy loss under is:
. For database , individual , and outcome , the privacy loss under is:
![\displaystyle PrivLoss_A(s)= \ln \frac{\Pr_A[A(DB+I)=s]}{Pr_A[A(DB)=s]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+PrivLoss_A%28s%29%3D+%5Cln+%5Cfrac%7B%5CPr_A%5BA%28DB%2BI%29%3Ds%5D%7D%7BPr_A%5BA%28DB%29%3Ds%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
Intuitively, this is meant to capture the “harm” incurred by individual I when the algorithm outputs . For example, if output is more likely with in the dataset than without , then when we see outcome we are more likely to think that was in the dataset, and the privacy loss is large. In particular, if the probability of is greater than 0 on , but 0 on database , then whenever occurs we know with certainty that was in the dataset. In this case, the privacy loss is infinite. On the other hand, if is equally likely with or without in the database, then outcome does not reveal any information about whether I was in the dataset, and the privacy loss is 0. If outcome is more likely without in the database than without , then when we see outcome we are less likely to think that was in the dataset, and the privacy loss is negative. Thus, privacy loss gives us a quantifiable measure of harm incurred by an individual. Note that in fact negative privacy loss might also be dangerous, as exposing non-participation might lead to harm, and so often we look at the absolute value of the privacy loss.
The Privacy Loss Random Variable. The notion of privacy loss defined above was tied to a specific outcome . We can analyze the privacy loss (or harm) incurred by participation in the analysis, by considering the privacy loss random variable. This is the random variable obtained by sampling an outcome , and then examining its privacy loss. For database and individual , the random variable 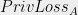 is sampled by running on to produce outcome , and outputting
is sampled by running on to produce outcome , and outputting  .
.
With this random variable in mind, note that -Differential Privacy simply means that for every and , the absolute value of is always bounded by . A relaxed guarantee, 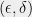 -Differential Privacy, simply means that with all but
-Differential Privacy, simply means that with all but 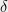 probability over the coins of , the absolute value of is bounded by .
probability over the coins of , the absolute value of is bounded by .
Expected Privacy Loss. Once we define the privacy loss random variable, we can begin to study its behavior. Of particular interest is its expectation. The expected privacy loss is:
![\displaystyle E_{s \leftarrow A(DB+I) } \left[ \ln \frac{\Pr_A [A(DB+I)=s]}{\Pr_A [A(DB)=s]} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%7Bs+%5Cleftarrow+A%28DB%2BI%29+%7D+%5Cleft%5B+%5Cln+%5Cfrac%7B%5CPr_A+%5BA%28DB%2BI%29%3Ds%5D%7D%7B%5CPr_A+%5BA%28DB%29%3Ds%5D%7D+%5Cright%5D&bg=eeeeee&fg=000000&s=0&c=20201002)
(in other words, this is the KL-divergence, or relative entropy, between ‘s output distributions on and on ).
I will elaborate on expected privacy loss and its relationship to composition, based on work with Cynthia Dowrk and Salil Vadhan, in a future post. But, as I warned above, I can’t resisit a brief teaser.
Irit Dinur, Cynthia Dwork and Kobbi Nissim were the first to analyze and bound the expected privacy loss. They did this for a particular algorithm (the binomial noise mechanism), and showed that the expected privacy loss is much smaller than the worst-case behavior. In the next post, I’ll show that this is true for any -DP algorithm: for small , the expected privacy loss is always bounded by  . This improved bound on the expected privacy loss (compared with the worst case guarantee) leads to significant improvements in our understanding of the way Differentially Private algorithms behave under composition, i.e. when an individual’s data are involved in many analyses.
. This improved bound on the expected privacy loss (compared with the worst case guarantee) leads to significant improvements in our understanding of the way Differentially Private algorithms behave under composition, i.e. when an individual’s data are involved in many analyses.

Awesome post, thanks!