In this post, I will present what I think is a simple(r) algorithm for estimating the 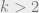 frequency moment, or simply the
frequency moment, or simply the  norm of a vector, in the sketching/streaming model. In fact, the algorithm is just a weak embedding of
norm of a vector, in the sketching/streaming model. In fact, the algorithm is just a weak embedding of  -dimensional into
-dimensional into 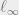 of dimension
of dimension 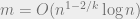 (this viewpoint spares me from describing the streaming model precisely).
(this viewpoint spares me from describing the streaming model precisely).
What do I mean by a weak embedding? We will get a randomized linear map 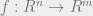 such that, for any
such that, for any 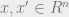 , we have that the image
, we have that the image  is a constant approximation to
is a constant approximation to  with some 90% probability. Since
with some 90% probability. Since  , the embedding is actually dimensionality-reducing.
, the embedding is actually dimensionality-reducing.
Before I jump into the algorithm, let me mention that the algorithm is essentially based on the approach from a paper joint with Robi Krauthgamer and Krzysztof Onak, and also the paper by Hossein Jowhari, Mert Saglam, and Gabor Tardos. At least our paper was itself inspired by the first (near-)optimal algorithm for frequency moment estimation of Piotr Indyk and David Woodruff (later improved by Lakshminath Bhuvanagiri, Sumit Ganguly, Deepanjan Kesh, and Chandan Saha).
The algorithm. Let  be the input vector of dimension . The algorithm just multiplies entry-wise by some scalars, and then folds the vector into a smaller dimension
be the input vector of dimension . The algorithm just multiplies entry-wise by some scalars, and then folds the vector into a smaller dimension  using standard hashing. Formally, in step one, we compute
using standard hashing. Formally, in step one, we compute 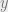 as
as

where random variable 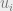 is drawn from an exponential distribution
is drawn from an exponential distribution  . In step two, we compute
. In step two, we compute  from using a random hash function
from using a random hash function ![h:[n]\to [m]](https://s0.wp.com/latex.php?latex=h%3A%5Bn%5D%5Cto+%5Bm%5D&bg=eeeeee&fg=666666&s=0&c=20201002) as follows:
as follows:

where  are just random
are just random 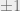 .
.
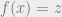 is the output, that’s it. In matrix notation,
is the output, that’s it. In matrix notation,  , where
, where 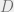 is a diagonal matrix and
is a diagonal matrix and 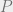 is a sparse
is a sparse  “projection” matrix describing the hash function
“projection” matrix describing the hash function 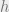 .
.
Of course the fun part is to show that this works (simple algorithm is not necessarily simple analysis). I’ll give essentially the entire analysis below, which shouldn’t be bad.
Analysis. We’ll first see that the infinity norm of is correct, namely approximates 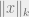 , and then that the infinity norm of is correct as well (both with constant approximation with constant probability of success). In other words, step one is an embedding into , and step two is dimensionality reduction.
, and then that the infinity norm of is correct as well (both with constant approximation with constant probability of success). In other words, step one is an embedding into , and step two is dimensionality reduction.
The claim about the infinity norm of follows from the “stability” property of the exponential distribution: if  are exponentially distributed, and
are exponentially distributed, and  are scalars, then
are scalars, then  is distributed as
is distributed as 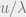 where
where  is also an exponential and
is also an exponential and  .
.
Now, applying this stability property for 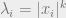 we get that
we get that 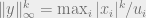 is distributed as
is distributed as 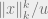 .
.
Note that we already obtain a weak embedding of 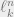 into
into 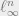 (i.e., no dimensionality reduction). We proceed to show that the dimension-reducing projection does not hurt.
(i.e., no dimensionality reduction). We proceed to show that the dimension-reducing projection does not hurt.
We will now analyze the max-norm of . The main idea is that the biggest entries of will go into separate buckets, while the rest of the “stuff” (small entries) will give a minor contribution only to each bucket. Hence, the biggest entry of will stick out in as well (and nothing bigger will stick out), preserving the max-norm. For simplicity of notation, let  , and note that the largest entry of is about
, and note that the largest entry of is about 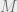 (as we argued above).
(as we argued above).
What is big? Let’s say that “big” is an entry of such that 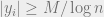 . With good enough probability, there are only at most
. With good enough probability, there are only at most 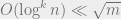 such big items (because of exponential distribution), so they will all go into different buckets.
such big items (because of exponential distribution), so they will all go into different buckets.
Now let’s look at the extra “stuff”, the contribution of the small entries. Let  be the set of small entries. Fix some bucket index
be the set of small entries. Fix some bucket index 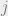 . We would like to show that the contribution of entries from that fall into bucket is small, namely, less than
. We would like to show that the contribution of entries from that fall into bucket is small, namely, less than  (the max entry of ).
(the max entry of ).
Let’s look at  . A straight-forward calculation shows that the expectation of
. A straight-forward calculation shows that the expectation of 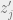 is zero, and the variance is
is zero, and the variance is ![E_{h,\sigma}[{z'}_j^2]=E_h[\sum_{i\in S:h(i)=j} y_i^2]\le \|y\|_2^2/m](https://s0.wp.com/latex.php?latex=E_%7Bh%2C%5Csigma%7D%5B%7Bz%27%7D_j%5E2%5D%3DE_h%5B%5Csum_%7Bi%5Cin+S%3Ah%28i%29%3Dj%7D+y_i%5E2%5D%5Cle+%5C%7Cy%5C%7C_2%5E2%2Fm&bg=eeeeee&fg=666666&s=0&c=20201002) . If only we now could show that
. If only we now could show that  , we would be done by Chebyshev’s inequality…
, we would be done by Chebyshev’s inequality…
How do we relate 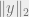 to ? Here comes the exponential distribution at rescue again. Note that
to ? Here comes the exponential distribution at rescue again. Note that ![E[\|y\|_2^2]=\sum_i x_i^2\cdot E[1/u_i^{2/k}]=\sum_i x_i^2\cdot O(1)=O(\|x\|_2^2)](https://s0.wp.com/latex.php?latex=E%5B%5C%7Cy%5C%7C_2%5E2%5D%3D%5Csum_i+x_i%5E2%5Ccdot+E%5B1%2Fu_i%5E%7B2%2Fk%7D%5D%3D%5Csum_i+x_i%5E2%5Ccdot+O%281%29%3DO%28%5C%7Cx%5C%7C_2%5E2%29&bg=eeeeee&fg=666666&s=0&c=20201002) since the expectation
since the expectation ![E[1/u^{2/k}]](https://s0.wp.com/latex.php?latex=E%5B1%2Fu%5E%7B2%2Fk%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) for an exponentially distributed is constant. Together with standard inter-norm inequality that
for an exponentially distributed is constant. Together with standard inter-norm inequality that 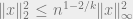 , we have that
, we have that ![E[\|y\|_2^2]\le O(n^{1-2/k} M^2)](https://s0.wp.com/latex.php?latex=E%5B%5C%7Cy%5C%7C_2%5E2%5D%5Cle+O%28n%5E%7B1-2%2Fk%7D+M%5E2%29&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Combining, we have that ![E[{z'}_j^2] \le O(n^{1-2/k} M^2/m)\le O(M^2/\log n)](https://s0.wp.com/latex.php?latex=E%5B%7Bz%27%7D_j%5E2%5D+%5Cle+O%28n%5E%7B1-2%2Fk%7D+M%5E2%2Fm%29%5Cle+O%28M%5E2%2F%5Clog+n%29&bg=eeeeee&fg=666666&s=0&c=20201002) , which is enough to apply Chebyshev’s and conclude that the “extra stuff” in bucket is
, which is enough to apply Chebyshev’s and conclude that the “extra stuff” in bucket is  with constant probability.
with constant probability.
We are almost done except for one issue: we would need the above for all buckets , and, in particular, we would like to have  for a fixed with high probability (not just constant). To achieve this, we use a stronger concentration inequality, for example the Bernstein inequality, which allows us exploit the fact that
for a fixed with high probability (not just constant). To achieve this, we use a stronger concentration inequality, for example the Bernstein inequality, which allows us exploit the fact that 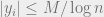 for
for  to achieve a high-probability statement.
to achieve a high-probability statement.
Discussion. The use of “stability” of exponential distribution is similar to Piotr Indyk’s use of  -stable distributions for sketching/streaming
-stable distributions for sketching/streaming 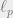 ,
, ![p\in(0,2]](https://s0.wp.com/latex.php?latex=p%5Cin%280%2C2%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , norms. Note that -stable distributions do not exist for
, norms. Note that -stable distributions do not exist for 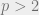 ; so here the notion of “stability” is slightly different. In the former, one uses the fact that for random variables
; so here the notion of “stability” is slightly different. In the former, one uses the fact that for random variables  , which are -stable, we have that
, which are -stable, we have that  is also -stable with well-controlled variance. In the latter case, we use the property that the max of several “stable” distributions is another one:
is also -stable with well-controlled variance. In the latter case, we use the property that the max of several “stable” distributions is another one: 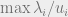 is distributed as
is distributed as 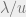 (i.e.,
(i.e.,  is “max-stable”). Note that this is useful for embedding into . As it turns out, such a transformation does not increase the
is “max-stable”). Note that this is useful for embedding into . As it turns out, such a transformation does not increase the 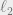 norm of the vector much, allowing us to do the dimensionality reduction in .
norm of the vector much, allowing us to do the dimensionality reduction in .
For streaming applications, the important aspects are the small final dimension  and the linearity of
and the linearity of  . This dimension of is optimal for this algorithm.
. This dimension of is optimal for this algorithm.
UPDATE: a preliminary write-up with formal details is available here.
