In memory of Mihai Pătraşcu.
Continuing the spirit of the previous post, in this post I will describe a specific technique for proving lower bounds for (static) data structures, when the space is (near) linear. This technique was introduced in the paper by Mihai and Mikkel Thorup, called “HIGHER lower Bounds for Near-Neighbor and F u r t h e r Rich Problems”.
Let’s start from the basics: how do we prove any data structure lower bound to start with? First of all, let’s fix the model: the cell-probe model, which is essentially the strongest of all, introduced by Yao in ’81. Here, the memory is composed of 

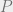
To be specific, here’s a sample problem 

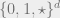

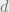



A very common approach to a lower bound in the cell probe model is via asymmetric communication complexity, as suggested by Peter Bro Miltersen, Noam Nisan, Shmuel Safra, and Avi Wigderson in ’95. The idea is to formulate the problem as a communication game. Alice represents the processor, and thus gets the query. Bob represents the memory, and hence gets the data structure. Their “communication game” is as one would expect: Alice and Bob communicate until they solve the problem. The asymmetry part comes from the fact that the input sizes are unequal, and hence we are attentive to how much information is sent from Alice to Bob, termed 
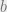
[MNSW’95] proved the following. Suppose there exists a solution to the data structure question, with 
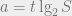
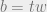
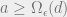


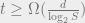


Such a lower bound is nice but it cannot quite differentiate between, say, cubic space versus linear space: just triple the query time and we’ve reduced the space to linear! This is of course not what happens in real data structures (I wish!). Part of the trouble comes from the fact that the communication game is more powerful than the data structure. In particular, Bob can remember what Alice has previously asked — which is clearly not the case in a data structure.
How can we prove a (higher) lower bound for a linear space data structure? Here come Mihai and Mikkel.
The idea is to ask for more! In particular, they consider several queries at the same time, by taking the 

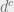



Here is a different, more formal intuition. Again take the 

Now comes the most interesting part (of this post at least): there actually exists a communication game that does a more efficient simulation than one which would just multiply all communication by 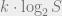


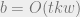
To obtain a Higher lower bound, it only remains to prove a communication complexity lower bound for the 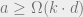


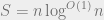
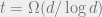
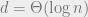
Final remarks. The original paper used a slightly weaker communication complexity lower bound for the partial match, which yielded a slightly weaker data structure lower bound. It has been strenghened to the above bound by Mihai using the LSD reduction (featured in the previous post), as well as by Rina Panigrahy, Kunal Talwar, and Udi Wieder in 2008, who have introduced a different method for showing lower bounds for near-linear space data structures. I should also mention that Mihai and Mikkel have actually first obtained a separation between polynomial and (near-)linear space in their earlier paper on predecessor search.
Good luck to all who have to deliver on promises made on June 26th.
