About a month ago, in our theory seminar, we had a talk by Paul Ohm. Paul is a Professor of Law at the University of Colorado and has done important work in the interface between Computer Science and the Law (which was also the title of his talk). There is much to report about this talk but here I’d like to discuss a side comment that caught my attention. The comment was (as far as my memory serves) that in various law and policy forums, whenever privacy concerns are raised, someone invokes the notion of Differential Privacy (see also here). Differential privacy is an extremely important notion of privacy for data analysis but what Paul was pointing out seems to be that differential privacy is sometimes raised as a way to shut the discussion on privacy rather than to start it. I’ll try to explain here how differential privacy and its generalizations can provide a framework for the social quest for privacy. Nevertheless, and here I am stating the obvious, no mathematical notion can replace the need for social debate. The right definition of privacy is context dependent and a matter for social choice. The approach I’ll discuss is based on work-in-progress with Salil Vadhan and discussions with Cynthia Dwork and Guy Rothblum.
What is Differential Privacy?
First, let me give some context on differential privacy. Consider a database 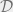

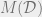
Consider two databases 




What is the Privacy in Differential Privacy?
While the opt-in opt-out characterization of differential privacy is important, it is not the whole story as far as privacy is concerned. The question for Alice may not be whether it’s better if
Let’s back up a little. How could Alice’s privacy be violated by releasing a differentially private sanitization of
Let us consider a few examples. Consider a medical database that consists of Alice’s record as well as the records of her immediate family. Obviously, sensitive information about Alice may be deduced from her family’s records. Fortunately, the property of differential privacy composes nicely and therefore the sanitization of the database would still be close (up to a slightly larger error parameter) to a sanitization of a database with the entire family of Alice removed. But what if the residents of Alice’s village are exposed to a pollutant which significantly increases several health risks? In such a case, Alice’s record is correlated with a large number of other individuals in a potentially very revealing manner. We may no longer be able to claim that a differentially private study of the database protects Alice’s privacy. Is this a failure of the definition of differential privacy? Not necessarily. After all, perhaps determining environmental health hazards is exactly why the database was created. Perhaps (depending on various factors), in such a case, sacrificing Alice’s privacy (indeed, the community’s privacy) for the greater good (and potentially also for Alice’s good) is acceptable. Another example is one where Alice is a smoker (and this information is public). We would probably not like to crush health studies on the health risks of smoking just because it predicts some health condition of Alice (who may or may not be a part of this study).
Let us sum up: (1) Differential Privacy has a very important opt-in opt-out interpretation, (2) In some cases (when there are very limited correlations between records), it protects the information of individuals, (3) In other cases (when there are more extensive correlations), differential privacy may not protect information of individuals, it was never designed to protect such information, and it may not even be desirable that such information would be protected. One should note though that even if most of Alice’s data is highly correlated with the rest of the database, differential privacy will still protect information that is “unique” to Alice, meaning information that cannot be deduced from the rest of the population.
A framework for interdisciplinary collaboration
Let us return to our poor regulator Carol who now realizes that the privacy offered by differential privacy is subtle. Carol is not a mathematician so how can she determine if differential privacy is the right notion in the specific context she is deciding about? And if differential privacy is insufficient, how can she specify a notion that is sufficient? I will try to briefly sketch a framework that can assist computer scientists and mathematicians to work together with legal scholars and policy makers to identify the right notions of privacy for various settings (and in fact, most of the presentation so far was guided by this perspective).
The idea could be thought of as “individual-oriented sanitization.” Assume for now that Alice is the only individual Carol cares about. In that case, there is no need for any sophisticated sanitization. Instead, let us allow Alice to make some changes to the database, from a predefined family of changes, in order to remove traces of her sensitive information. Now Carol needs to decide how far she should go in order to protect Alice’s privacy. What is a legitimate expectation of privacy on Alice’s part? Every set of individual-oriented sanitization would translate to a formal notion of privacy.
For example, is it reasonable to allow Alice to remove her own record and the records of a few others? In many cases the answer is yes, and if this is the only changes we would like to allow then (the usual notion of) differential privacy is the right notion to use. The magic of differential privacy is that it simultaneously guarantees this level of privacy for all individuals while preserving some utility (whereas if we allowed every individual to remove her own record we would be left with an empty and thus useless database). As a side comment, I would like to point out that one can show that asking for this level of protection for every individual is not only implied by differential privacy but rather equivalent to it.
Is differential privacy the right notion always? Let’s look at a couple of other examples which indicate it is not. Consider a database containing the Facebook data of different individuals. Perhaps now we would like to allow Alice to remove her entire record as well as her messages and pictures from the records of her neighbors. If the neighborhood of individuals can be large, this implies a different notion than differential privacy where specific kind of data can be erased from many records. (Note that notion of “node-level” privacy were discussed in previous works on differential privacy for graphs, e.g. here.) Another example is a database that contains many different kinds of attributes for each individual. In such a case, Alice may still want to remove medical attributes about her family members, but she may also want to remove the salary attributes about some of her coworkers and the “my acquaintances” attributes of members of her Alcoholics Anonymous meetings, and so on. So now we may allow Alice to change a few records for every attribute (but different records for different attributes).
While the above discussion is non-technical, it translates in each case to a formal definition of privacy that generalizes differential privacy. In the second example for instance we can now define two databases
Summing up the framework we suggest, we could imagine that legal scholars and policy makers would concentrate on defining the reasonable expectation of privacy for an individual. This would translate to a definition of privacy which should allow computer scientists to study what kind of utility can be preserved under such privacy constraint (indeed, several of the positive results for Differential Privacy naturally extend to a setting where we define neighboring databases more generally). The results of this study could feedback into additional refinements of the privacy definitions.
Extensions on Fairness and Privacy
The generalizations of differential privacy discussed here are related to a recent study of fairness in classification. Beyond the technical connection, a conceptual connection is that one of the conclusions of that work is that fairness is also a social choice. I hope that in future posts I will discuss fairness and also privacy in more challenging settings (such as in on-line behavioral targeting). There are many more details to consider, for example how machine learning and statistics could assist in identifying correlations which could influence the definition of privacy.

There are, of course, several other barriers to using differential privacy in practice. One is the question of how to set the epsilon. Another is that no matter what epsilon is set to, a user’s data may be present in an unknown number of databases overall. Finally, there appear to be several scenarios where differential privacy and utility are incompatible (though I suppose we do not yet fully understand to what extent this is inherent, and to what extent it is a limitation of current techniques).
The question of how to set epsilon comes up a lot. A similar hard question is “what is your time worth?” You get some number of hours in life, and then you die. Still, we’ve figured out how to use “dollars per hour” as a basis for exchanging time for money. A better (in my view) way of thinking about differential privacy is that it is a common currency that folks can now use as the basis for the exchange of privacy for utility.
The user’s data in multiple datasets problem is something that has several technological answers, going forward. Systems like PINQ use capabilities for sensitive data, which prevents copying and distributing the data. There are probably good crypto approaches analogous to digital cash (out of my element here), ensuring that a certain level of access to a record can’t be “respent”. Legacy data are probably out of luck, but there is no reason not to think about how to keep new valuable data from spreading (and devaluing). Bringing the currency analogy back, this was obviously an issue any currency needs to face before anyone takes it seriously, but it is totally doable. You should do it. =)
Thank you Jonathan, you are raising several important issues that deserve a separate treatment (and indeed I may try to discuss some of them in the future). But the focus of my post was different – how can non mathematicians understand and debate notions of privacy. One point you are making is that beyond obtaining a “qualitative understanding”, policy makers need to be able to understand privacy quantitatively (via the choice of the error parameter). This is definitely valid.
As for barriers to using differential privacy in practice, you are correct and this is just the tip of the iceberg. Implementation and system considerations may be a more pressing barrier. As both of us know, many examples of the barriers any theoretical concept faces can be found in the area of Cryptography. What make privacy even more complicated are the inherent tradeoffs that need to be accepted. There is no way to get everything we want in terms of utility and privacy. In addition, we are dealing with so many agents. All of this may drive us to feel that privacy is a lost cause. I cannot accept this point of view. What is clear to me is that privacy will require an involvement of society (in the form of social norms, regulations and laws). Tradeoffs will remain, but society needs to be informed about them. My post sketches a small step in this direction.
Till I discuss your points in more depth, here (http://people.seas.harvard.edu/~salil/research/PrivateBoosting-abs.html) is an important work on the accumulation of error in differential privacy, and here (http://research.microsoft.com/apps/pubs/default.aspx?id=138390) is one of the attempts towards the implementation of differential privacy.
Omer,
Nice post! I think this is the place I’ve so far seen the basic points about interpreting differential privacy best articulated (notably the section on “What is the Privacy in Differential Privacy?”).
As to the framework for interdisciplinary collaboration, it is not clear to me how much more “human-interpretable” the framework really is than the original definition. The fact that the exact metric on distributions is so important to differential privacy suggests that a lot is lost when you switch to a high-level interpretation of the type you’re proposing. And, as Jon mentioned, the meaning of epsilon is tricky to pin down.
Good to get a conversation going,
Adam
Thanks Adam, you are very kind!!
The conversation is really what it’s all about, so thanks for picking the glove 🙂
It sounds like what you are saying is more that the framework oversimplifies and over-abstractifies the mathematical definition, rather than that it’s not more human friendly (which I do think it is). Am I missing your point? It is clear that some level of abstraction is needed if we want non-mathematicians to be able to debate notions of privacy. The question is whether we got the right level. I tried to demonstrate that this level of abstraction may lead to unexpected but still very natural new notions of privacy (that are easy to formalize mathematically), and this is in my mind some positive evidence regarding the framework.
The concrete question you raise is whether losing details like the exact metric between distributions and the setting of the error parameter, may give a false interpretation. This is something to be aware of and careful about, but I do not think it invalidates the usefulness of the framework. By the way, don’t you agree that the exact metric in the definition of differential privacy has a very intuitive interpretation? I think that the interpretation is consistent with the framework I discussed. I definitely accept Jon and your comment about the choice of the error parameter (and indeed in some cases, there is no setting of the parameter that will guarantee both privacy and utility). Seems worthy of a separate post ..
It sounds like what you are saying is more that the framework oversimplifies and over-abstractifies the mathematical definition, rather than that it’s not more human friendly (which I do think it is).
Yes, that’s a better way of putting it.
The concrete question you raise is whether losing details like the exact metric between distributions and the setting of the error parameter, may give a false interpretation. This is something to be aware of and careful about, but I do not think it invalidates the usefulness of the framework.
I didn’t mean to suggest the framework was invalid, just that we have to watch out that our intuitive interpretation not lose pace with the math. For example, even with “approximate” notions of differential privacy (the ones with the delta in them — as you know, there are a few of them) the interpretation (say in terms of how an adversary’s beliefs change) becomes more delicate. See here for an example of that.
Still, it does seem like a natural way to generate generalizations of differential privacy that can subsequently be studied further.
By the way, don’t you agree that the exact metric in the definition of differential privacy has a very intuitive interpretation?
I think it’s a beautiful, intuitively meaningful definition that dances to life on the page when I gaze upon it. But I may be biased. As the saying goes, intuition is in the lower brain functions of the beholder.
At least your biases are so poetic … 🙂
On the exact metric between distributions being important:
The only convincing explanation I’ve seen for why the definition of differential privacy uses a multiplicative notion of distance is described in the paper that Adam links to (http://arxiv.org/abs/0803.3946). Specifically, differential privacy defined with this multiplicative notion of distance is equivalent to requiring that an adversary’s posterior beliefs about an individual (after seeing the output of the mechanism) are “close” to an adversary’s prior beliefs about an individual, at least when we condition on the rest of the database. The nice thing about the latter formulation is that it doesn’t really matter what metric we use for measuring the distance between the prior and posterior, since the equivalence holds even if we restrict to distributions of support size 2 (in which case all natural metrics are equivalent to each other). Moreover, Adam’s paper shows that (eps,delta)-differential privacy amounts to requiring that the prior and posterior are close w.p. ~1-delta over the coins of the mechanism, thus explaining (for me) why (eps,delta)-differential privacy is essentially as good as eps-differential privacy when delta is negligibly small. [Adam, please correct me if I’m wrong about this.]
The generalization of differential privacy described in Omer’s post amounts to the following: consider any individually-oriented sanitization S (e.g. a database with some fields removed), and suppose we reveal S to an adversary. Then the beliefs the adversary has about the database that led to S don’t change much upon revealing the outcome of the mechanism (with all but negligible probability).
Perhaps this is a qualitative description that does not lose too much of the important mathematical details?
Salil